Abstract
Generative Adversarial Networks (GANs) are a new type of generative models, which belong to a branch of unsupervised learning in machine learning and are used to create images. The word “adversarial” refers to the two networks involved, the “generator” and the “discriminator”, which are locked in a battle. From a game-theoretical perspective, they are competing against each other in a zero-sum game.
The generator network tries to create realistic looking images from a “code vector” and fool the discriminator network, which in contrast tries to detect if an image shown is real. After initial approaches with fully connected layers, the introduction of convolutional layers for both parts of the networks led to significant improvements in the quality of the images generated. Experiments with the input code also showed the applicability of GANs for representation learning. Thereby, part of the code was found to be tied to specific features or objects, which encodes a representation of the real world. Some remarkable experiments even showed that arithmetic operations like subtraction and addition on the latent space led to the expected semantic changes in the image. This allows for fine-tuning the final image by incrementally altering the input code.
GANs are thereby a very promising new approach to representation learning, which imply many future applications. As an example, Facebook is experimenting with GANs to create photorealistic images, which can be used to create targeted content for advertising (9).
Motivation Generative Models & Unsupervised Learning
There is a tremendous amount of information in our physical and digital world and a significant fraction of it is easily accessible. The challenging part for machines and humans is to develop a reasoning for this large quantity of data. Our natural approach is trying to find patterns and models that help us describe what we see. We often instinctively use representations to reduce complexity and make things easier to process.
One of the core aspects of neural networks in general is the lower dimension of their output compared to the dimension of the data they are trained on. So somehow these networks are forced to discover and efficiently internalize the essence of the data presented. This very well describes the idea of unsupervised learning, which aims at finding patterns in data. Mastering an unsupervised learning task paves the way to finding reliable representations of images and finally allows and enhances generative models. The GAN as one type of generative model is introducing CNNs to the challenging task of unsupervised learning after their great breakthroughs in supervised learning.
The GAN Concept
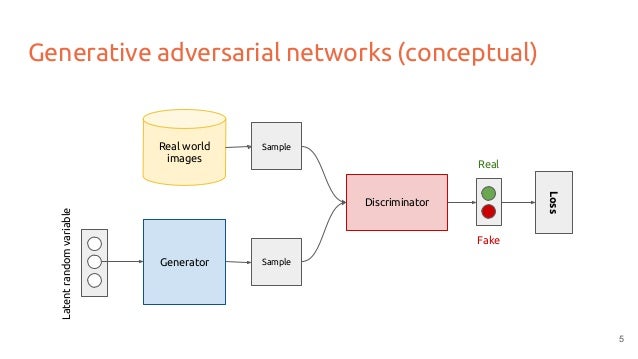
The GAN concept solves the problem of training a generative network (G) by introducing a second discriminative network (D). The setup is referred to as adversarial, since D and G are in a constant battle against each other, as illustrated in figure 1. While G tries to create increasingly more realistic images to fool D, D is constantly adapting its parameters to make a more informed decision. As figure 2 shows, this yields two scenarios: On the left, a real image is shown to D directly and D tries to classify it as real as confidently as possible. On the right, an image is generated by G and then shown to D. While D tries to drive its prediction of real on the generated image to 0, G tries to push it into the opposite direction by creating more realistic images.
In the original setup introduced by Goodfellow et al. (1), fully connected layers were used for both D and G. However, the usage of convolutional layers showed even greater potential and is the current state-of-the-art (2).
The setup can be interpreted as a zero-sum game within game theory, which follows a min-max character. On the one hand, D tries to maximize the probability of correctly distinguishing between real and fake data by changing its decision boundary. On the other hand, G tries to minimize the probability of its generated samples being classified as fake.
The outcome of the game is fed back to both networks using back-propagation. This allows both networks to iteratively improve their policy on how to decide and act within their respective tasks.
In terms of game theory, training a GAN requires finding Nash equilibria in high-dimensional, continuous, non-convex games. This is an incredibly hard task with no clear solution strategy to it.
Mathematically, the dataset of real images is a number of examples drawn from a true data distribution, which is shown in blue in figure 3. G takes a code as an input, e.g., taken from a unit Gaussian distribution z, and tries to generate a distribution \hat p(x) similar to the true distribution p(x). G is constantly trying to adjust its parameters \theta to stretch and squeeze the input to better match the true distribution.
Figure 4 gives us a good impression how G tries to fit its distribution to the true distribution (black dots) while D adapts the decision boundary to best distinguish between the generated and real data. We see in (a) the initial setup, (b) where D has updated its decision boundary, (c) where G has updated its distribution by shifting into the same direction as D has shifted its decision boundary, and finally (d) where we have reached the final equilibrium where G is perfectly mimicking the true data distribution and D can only decide randomly, indicated by the uniform decision boundary.

Figure 1: GAN concept: D tries to correctly detect, if images came from real world examples or G. G as the adversary tries to improve its image generation to fool D. Source: Link

Figure 2: Two scenarios: On the left, training examples x are randomly sampled from the training set and used as input for D. On the right, inputs z to G are randomly sampled from the model’s prior over the latent variables. D then receives input G(z), a fake sample created by G. Source: (7)

Figure 3: Representation of distribution space. Source: (8)

Deep Convolutional GANs
A big breakthrough in the research about GANs has been achieved through the Deep Convolutional GAN (DCGAN) by Radford et al. (2) who applied a list of empirically validated tricks as the substitution of pooling and fully connected layers with convolutional layers. For G, a fractional stride was utilized while D used integer stride. The network takes 100 random numbers drawn from a uniform distribution (the so-called code or latent variables) as an input. The generator network then creates a 64x64 color image.
By changing the code incrementally, we observe meaningful changes in the generated images, while remaining real-looking. This is a clear sign that the network has learned actual representation or features of how the world looks like and it has encoded this information in the network.
The procedure of incrementally changing parts of the input code is described as walking in the latent space. As an example, we could perform a stepwise interpolation between two codes and see how the result changes. One experiment in the DCGAN publication (2) trained a network on images of bedrooms. An interpolation between the code of two different bedrooms showed how the rooms are slowly transforming while constantly keeping the look of a bedroom. In figure 5 we can observe lamps turning into windows (first row) or a TV transforming into a large window (last row).
Another evidence that the network has learned representations can be found in visualizing the filters of the network in figure 6. We can clearly see that the untrained, random filters look almost like a single sample picture. However, the trained filters have clearly discovered features that are significant for a bedroom.
Another remarkable observation is that the input codes support vector arithmetic. This means if we take, e.g., the averaged code of three smiling women, subtract neutral women, add neutral men and then feed the resulting code through the network, we get a smiling man (as shown in figure 7).

Figure 4: DCGAN generator: A series of fractionally-strided convolutions convert the input vector (code) into an image (G(z)) Source: created from (7)

Figure 5: Series of interpolations between two random input vectors. Source: created from (2)

{kind=link}

Figure 7: Vector arithmetic for visual concepts. Source: (2)
Recent Improvements
The power of the features encoded in the latent variables was further explored by Chen at al. (4). They made use of the fact that the latent space of a regular GAN is underspecified to add additional input parameters (referred to as extend code) and thereby functionality. They decomposed the code in the latent code seen before and an additional latent component, which targets the semantic features of the data distribution. The goal is to learn disentangled and interpretable representations.
This is achieved by maximizing the mutual information between small subsets of the representation variables and observations. Therefore, Chen at al. introduced a regularization term that gives weight to an entropy based indicator of how much information is shared between the latent code and the generated distribution.
The publication showed remarkable results. In the MNIST (10). dataset the digit type, rotation, and width of the digits was captured in separate designated parts of the additional latent component. On a 3D faces data set the azimuth, elevation, lighting, and the width of the face were captured and identified.
GANs have also been used in the field of semi-supervised learning, where a small amount of labeled data is combined with a large amount of unlabeled data. In this setting, D is a classifier with output dimension of n+1 that gives weight to the n classes to be identified plus a variable indicating if the image is real or not.
This allows the classifier to be additionally trained with unlabeled data which is known to be real, and with samples from the generator, which are known to be fake.
Through this approach, named feature matching GANs, good performance on the MNIST data set can be achieved with as little as 20 labeled training examples. (3)


Figure 8: Manipulating latent codes on MNIST. Source: (4)
State-of-the-Art & Outlook
Today, most GANs are loosely based on the former shown DCGAN (2) architecture. Many papers have focused on improving the setup to enhance stability and performance.
Some key insights where: (3)
- Usage of convolution with stride instead of pooling
- Usage of Virtual Batch Normalization
- Usage of Minibatch Discrimination in D
- Replacement of Stochastic Gradient Decent with Adam Optimizer (6)
- Usage of one-sided label smoothing
GANs are very promising generative models that have shown great potential in the fields of image generation and manipulation. Besides some imperfections in the image quality, there is a special need for a profound theoretical understanding to enable better training algorithms. In addition, GANs can potentially improve other fields like reinforcement learning, which can significantly benefit from creating an efficient and sparse understanding of our environment.
Literature
1) Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Nets. In Advances in neural information processing systems (pp. 2672-2680).
2) Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv preprint.
3) Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems (pp. 2226-2234).
4) Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Advances in Neural Information Processing Systems (pp. 2172-2180).
5) Goodfellow, I. (2016). NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv preprint.
6) Kingma, D., & Ba, J. (2014). Adam: a Method for Stochastic Optimization. arXiv preprint.
7) Goodfellow, I. (2016). NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv preprint arXiv:1701.00160.
Weblinks
8) Generative Models. (2016). Open AI Research Blog Post.
9) When Will Computers Have Common Sense?. (2016). Larry Greenemeier.
10) MNIST Data Set. (1998). Yann LeCun, Corinna Cortes, Christopher J.C. Burges.