Convolutional neural networks are built by concatenating individual blocks that achieve different tasks. These building blocks are often referred to as the layers in a convolutional neural network. In this section, some of the most common types of these layers will be explained in terms of their structure, functionality, benefits and drawbacks.
This section is an excerpt from Convolutional Neural Networks
Convolutional Layer
The main task of the convolutional layer is to detect local conjunctions of features from the previous layer and mapping their appearance to a feature map. As a result of convolution in neuronal networks, the image is split into perceptrons, creating local receptive fields and finally compressing the perceptrons in feature maps of size m_2 \ \times \ m_3. Thus, this map stores the information where the feature occurs in the image and how well it corresponds to the filter. Hence, each filter is trained spatial in regard to the position in the volume it is applied to.
In each layer, there is a bank of m_1 filters. The number of how many filters are applied in one stage is equivalent to the depth of the volume of output feature maps. Each filter detects a particular feature at every location on the input. The output Y_i^{(l)} of layer l consists of m_1^{(l)} feature maps of size m_2^{(l)} \ \times \ m_3^{(l)}. The i^{th} feature map, denoted Y_i^{(l)}, is computed as
| (1) | Y_i^{(l)} = B_i^{(l)} + \sum_{j=1}^{m_1^{(l-1)}} K_{i,j}^{(l)} \ast Y_j^{(l-1)} |
where B_i^{(l)} is a bias matrix and K_{i,j}^{(l)} is the filter of size 2h_1^{(l)} + 1 \ \times \ 2h_2^{(l)} + 1 connecting the j^{th} feature map in layer (l-1) with i^{th} feature map in layer.
The result of staging these convolutional layers in conjunction with the following layers is that the information of the image is classified like in vision. That means that the pixels are assembled into edglets, edglets into motifs, motifs into parts, parts into objects, and objects into scenes.
Original version of the page created by Simon Pöcheim can be found here.
Non-Linearity Layer
A non-linearity layer in a convolutional neural network consists of an activation function that takes the feature map generated by the convolutional layer and creates the activation map as its output. The activation function is an element-wise operation over the input volume and therefore the dimensions of the input and the output are identical.
In other words; let layer l be a non-linearity layer, it takes the feature volume Y_i^{(l-1)} from a convolutional layer (l-1) and generates the activation volume Y_i^{(l)}:
| Y_i^{(l)} = f(Y_i^{(l-1)}) |
with,
| Y_i^{(l)}\in \mathbb{R}^{m_1^{(l)}\times m_2^{(l)}\times m_3^{(l)}}\\ Y_i^{(l-1)}\in \mathbb{R}^{m_1^{(l-1)}\times m_2^{(l-1)}\times m_3^{(l-1)}}\\ m_1^{(l)}=m_1^{(l-1)} \wedge m_2^{(l)}= m_2^{(l-1)} \wedge m_3^{(l)}=m_3^{(l-1)} |
This can also be interpreted as m_1^{(l-1)} number of 2-dimensional feature maps (generated by m_1^{(l-1)} number of filters in convolutional layer (l-1)) each with size m_2^{(l-1)}\times m_3^{(l-1)}.
In some publications(2) a gain koefficient is added to the activation function in order to cope up with the vanishing gradient problem:
| Y_i^{(l)} = g_i f(Y_i^{(l-1)}) |
Similar to multilayer perceptrons, the activation function is generally implemented as logistic (sigmoid) or hyperbolic tangent functions. However, more recent research suggests rectified linear units (ReLUs) are advantageous over the traditional activation functions particularly in convolutional neural networks (3).
It is noteworthy that, although this wiki seperates the non-linearity layer from convolutional layer, it is not uncommon to see a combination of the non-linearity layer with the convolutional layer in the literature. Some of the works use different notations for their layer and architecture description. In some publications(2) of Yann LeCun for example, the combined layer is named a filter bank layer and represented as {F_{CSG}} denoting a convolutional layer (C) with a hyperbolic tangent activation function (S) and gain coefficients (G) .
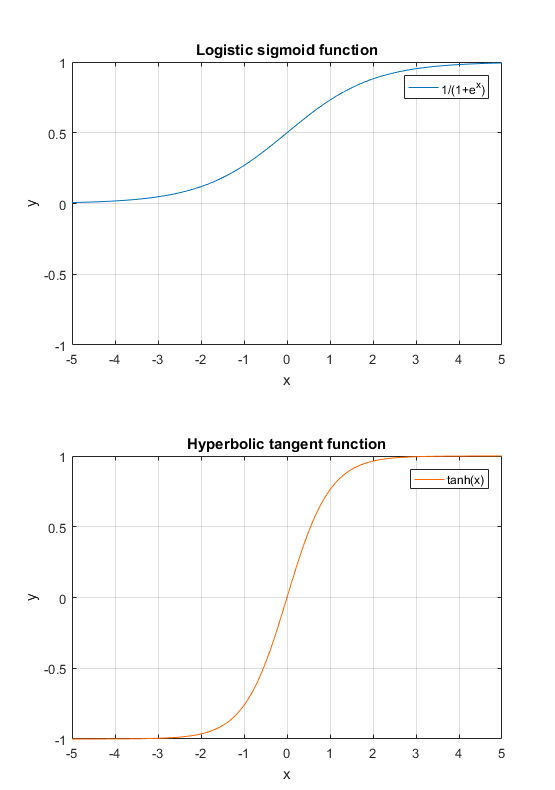 Logistic (sigmoid) and hyperbolic tangent functions are commonly used activation functions in convolutional neural networks.
Logistic (sigmoid) and hyperbolic tangent functions are commonly used activation functions in convolutional neural networks.
Rectification Layer
A rectification layer in a convolutional neural network performs element-wise absolute value operation on the input volume (generally the activation volume). Let layer l be a rectification layer, it takes the activation volume Y_i^{(l-1)} from a non-linearity layer (l-1) and generates the rectified activation volume Y_i^{(l)}:
| Y_i^{(l)} = |Y_i^{(l-1)}| |
Similar to the non-linearity layer, the element-wise operation properties do not change the size of the input volume and therefore, these operations can be (and in many cases(1) including AlexNet(4) and GoogLeNet(5) are) merged into a single layer:
| Y_i^{(l)} = | f(Y_i^{(l-1)})| |
Regardless of the general simplicity of the operation, it plays a key role in the performance of the convolutional neural network by eliminating cancellation effects in subsequent layers. Particularly when an average pooling method is utilized, the negative values within the activation volume are prone to cancel out the positive activations, degrading the accuracy of the network significantly. Therefore, the rectification is named as a "crucial component" (2).
Rectified Linear Units (ReLU)
The rectified linear units (ReLUs) are a special implementation that combines non-linearity and rectification layers in convolutional neural networks. A rectified linear unit (i.e. thresholding at zero) is a piecewise linear function defined as:
| Y_i^{(l)} = max(0,Y_i^{(l-1)}) |
The rectified linear units come with three significant advantages in convolutional neural networks compared to the traditional logistic or hyperbolic tangent activation functions:
- Rectified linear units propagate the gradient efficiently and therefore reduce the likelihood of a vanishing gradient problem that is common in deep neural architectures.
- Rectified linear units threshold negative values to zero, and therefore solve the cancellation problem as well as result in a much more sparse activation volume at its output. The sparsity is useful for multiple reasons but mainly provides robustness to small changes in input such as noise (6).
- Rectified linear units consist of only simple operations in terms of computation (mainly comparisons) and therefore much more efficient to implement in convolutional neural networks.
As a result of its advantages and performance, most of the recent architectures of convolutional neural networks utilize only rectified linear unit layers (or its derivatives such as noisy or leaky ReLUs) as their non-linearity layers instead of traditional non-linearity and rectification layers.
In works such as AlexNet(4) rectified linear units are shown to operate six times faster then hyperbolic tangent non-linearities while reaching 25% error rate on CIFAR-10 dataset(7). More recently, utilization of an advanced derivative Parametric Rectified Linear Units (PReLU) allowed convolutional networks to surpass human-level performance in ImageNet database (8). More information on the advantages of the rectified linear units in convolutional neural networks can be found in (3).
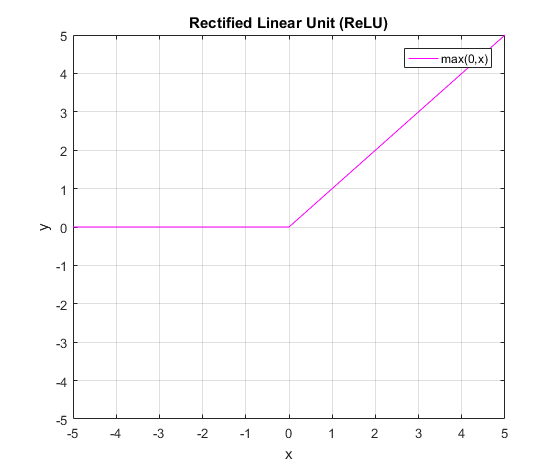 Rectified linear units are becoming more popular among their counterparts due to their simplicity and multiple advantages.
Rectified linear units are becoming more popular among their counterparts due to their simplicity and multiple advantages.
Pooling Layer
The pooling or downsampling layer is responsible for reducing the spacial size of the activation maps. In general, they are used after multiple stages of other layers (i.e. convolutional and non-linearity layers) in order to reduce the computational requirements progressively through the network as well as minimizing the likelihood of overfitting.
The pooling layer l has two hyperparameters, the spatial extent of the filter F^{(l)} and the stride S^{(l)}. It takes an input volume of size m_1^{(l-1)}\times m_2^{(l-1)}\times m_3^{(l-1)} and provides an output volume of size m_1^{(l)}\times m_2^{(l)}\times m_3^{(l)} where;
| m_1^{(l)} = m_1^{(l-1)}\\ m_2^{(l)} =(m_2^{(l-1)}-F^{(l)})/S^{(l)} +1\\ m_3^{(l)} =(m_3^{(l-1)}-F^{(l)})/S^{(l)} +1 |
The key concept of the pooling layer is to provide translational invariance since particularly in image recognition tasks, the feature detection is more important compared to the feature's exact location. Therefore the pooling operation aims to preserve the detected features in a smaller representation and does so, by discarding less significant data at the cost of spatial resolution.
The pooling layer operates by defining a window of size F^{(l)}\times F^{(l)} and reducing the data within this window to a single value. The window is moved by S^{(l)} positions after each operation similarly to the convolutional layer and the reduction is repeated at each position of the window until the entire activation volume is spatially reduced.
It is noteworthy that the window for pooling layers does not have to be a square and can be parametrised with F_1^{(l)} and F_2^{(l)} resulting in a rectangle of size F_1^{(l)}\times F_2^{(l)}. However, this is extremely uncommon and is therefore left out of the notation is most of the publications, including this wiki.
The most common methods for reduction are max pooling and average pooling. Max pooling operates by finding the highest value within the window region and discarding the rest of the values. Average pooling on the other hand uses the mean of the values within the region instead.
Max pooling has demonstrated faster convergence and better performance in comparison to the average pooling and other variants such as l^2-norm pooling (9). Thus, recent work generally trends towards max pooling or similar variants.
Apart from the reduction method, the hyperparameter selections determine whether the pooling windows overlap or not. In case F^{(l)}> S^{(l)} the pooling windows overlap on top of each other, filtering some of the data points multiple times. Depending on this condition, a pooling layer is named overlapping or non-overlapping pooling.
Even though the overlapping window method has been used with success to some extent and some of the research(4) suggests that it can reduce the chance of overfitting on certain datasets, the larger spatial size F^{(l)} in pooling layers is generally considered destructive (13). Therefore, the most commonly used pooling parameters are F^{(l)} = 2 , S^{(l)} = 2 which is non-overlapping.
The selection of F^{(l)} = 2 , S^{(l)} = 2 is the smallest feasible integer sized filter, however, it still discards 75% of the data.This aggressive reduction executed by pooling layers can limit the depth of a network and ultimately limit the performance. This problem has pushed the research to find other methods to improve or replace the pooling layer.
One approach is to use smaller "fractional" filters(10) instead of common ones. Another option is to remove pooling layers completely and simply perform the reduction by increasing the stride in convolutional layers (11). These solutions still remain as active research topics.
It is important to note that some of the cutting edge architectures such as GoogLeNet's Inception Modules also feature 1\times 1 convolutions to reduce the dimensions of the activation volume before a 3\times 3 or 5\times 5 convolutional layer. These are not considered as pooling layers since the reduction is not happening stritctly spatially but along the depth axis. However, the architecture of the GoogLeNet still features max and average pooling layers between the inception modules apart from its 1\times 1 convolutions. (5)
![]()
GoogLeNet's Inception Module architecture depicting the underlying 1\times 1 convolutions. (Image source (5))
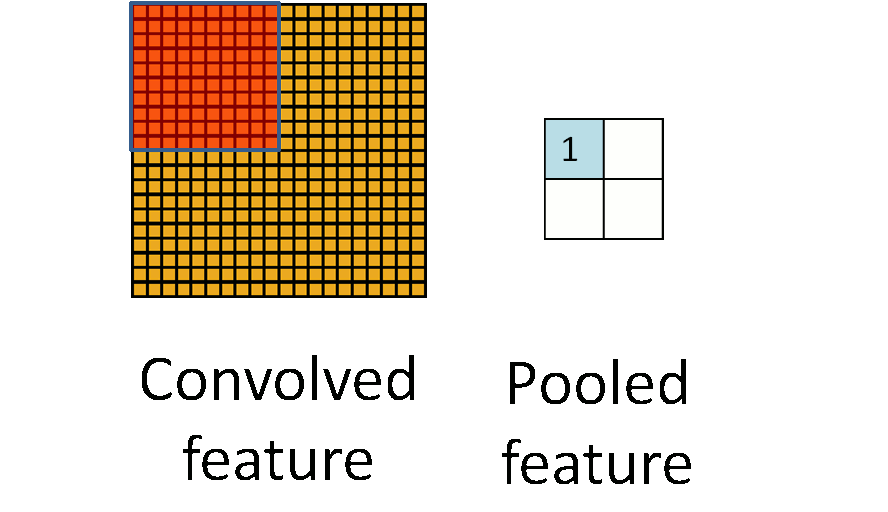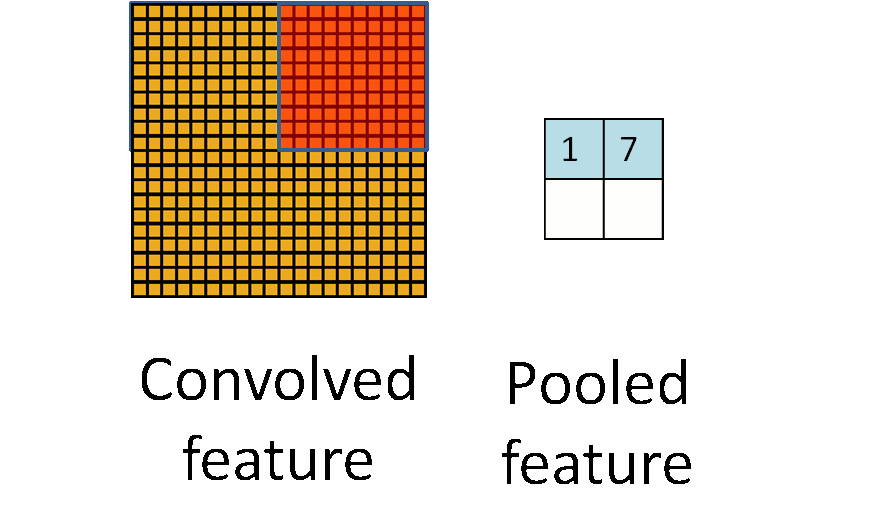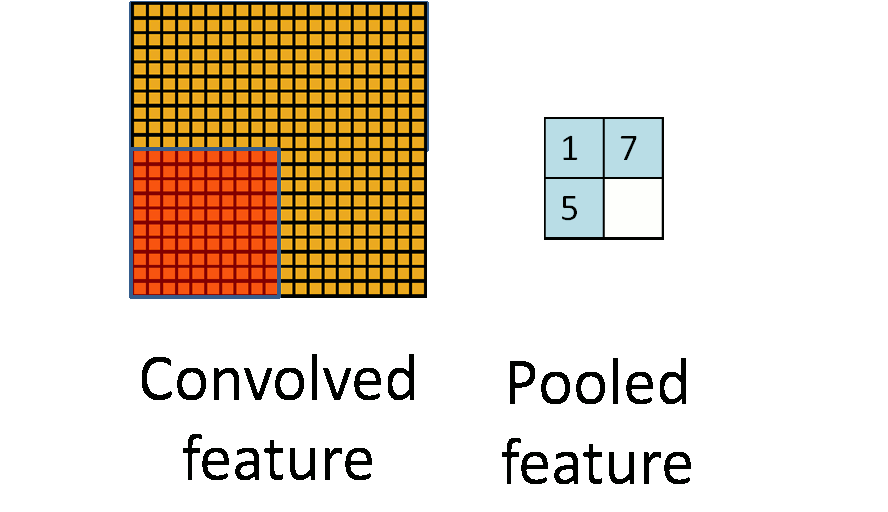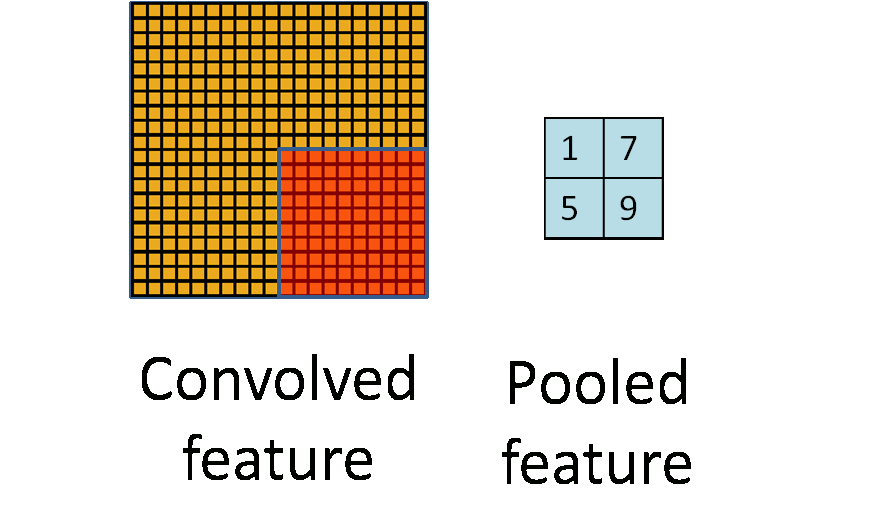
An animation depicting a 20 \times 20 input being reduced to 2\times 2 output using F^{(l)}=10 and S^{(l)}=10 non-overlapping pooling operation. (Image source (12))
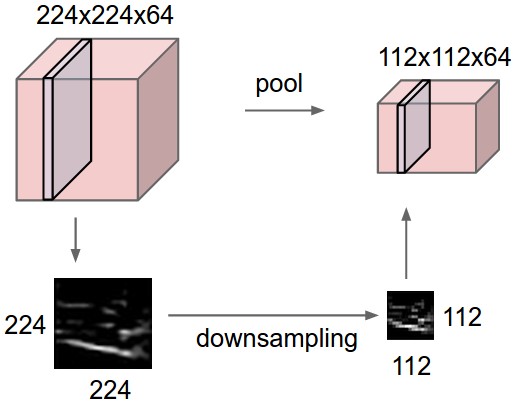
Pooling is performed spatially on each 2-dimensional map within the volume. As a result the depth of the output volume is the same as the input volume.(Image source (13))

Non-overlapping max pooling on a 2-dimensional 4\times 4 input. 75% of the data is discarded in the resulting 2\times 2 output.(Image source (12))
Fully Connected Layer
The fully connected layers in a convolutional network are practically a multilayer perceptron (generally a two or three layer MLP) that aims to map the m_1^{(l-1)}\times m_2^{(l-1)}\times m_3^{(l-1)} activation volume from the combination of previous different layers into a class probability distribution. Thus, the output layer of the multilayer perceptron will have m_1^{(l-i)} outputs, i.e. output neurons where i denotes the number of layers in the multilayer perceptron.
The key difference from a standard multilayer perceptron is the input layer where instead of a vector, an activation volume is taken as the input. As a result the fully connected layer is defined as:
If l-1 is a fully connected layer;
| y_i^{(l)} = f(z_i^{(l)}) \quad \text{with} \quad z_i^{(l)}= \sum_{j=1}^{m_1^{(l-1)}} w_{i,j}^{(l)} y_i^{(l-1)} |
otherwise;
| y_i^{(l)} = f(z_i^{(l)}) \quad \text{with} \quad z_i^{(l)}= \sum_{j=1}^{m_1^{(l-1)}} \sum_{r=1}^{m_2^{(l-1)}} \sum_{s=1}^{m_3^{(l-1)}} w_{i,j,r,s}^{(l)} \Big(Y_i^{(l-1)}\Big)_{r,s} |
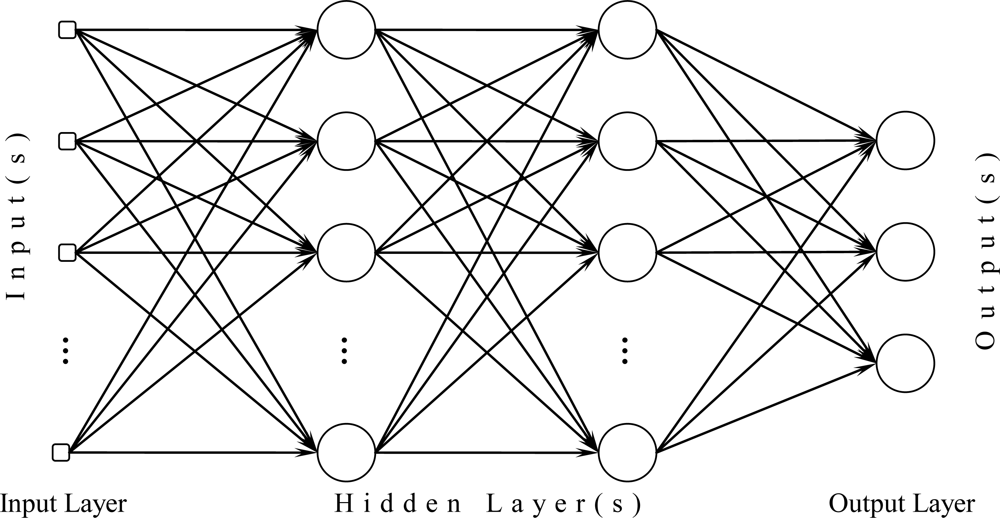
A three layer fully connected multilayer perceptron structure that is identical to a fully connected layer in convolutional neural networks with only difference being the input layer.(Image source)
The goal of the complete fully connected structure is to tune the weight parameters w_{i,j}^{(l)} or w_{i,j,r,s}^{(l)} to create a stochastic likelihood representation of each class based on the activation maps generated by the concatenation of convolutional, non-linearity, rectification and pooling layers. Individual fully connected layers operate identically to the layers of the multilayer perceptron with the only exception being the input layer.
It is noteworthy that the function f once again represents the non-linearity, however, in a fully connected structure the non-linearity is built within the neurons and is not a seperate layer.
As a contradiction, according to Yann LeCun, there are no fully connected layers in a convolutional neural network and fully connected layers are in fact convolutional layers with a 1\times 1 convolution kernels (14). This is indeed true and a fully connected structure can be realized with convolutional layers which is becoming the rising trend in the research.
As an example; the AlexNet(4) generates an activation volume of 512\times7\times7 prior to its fully connected layers dimensioned with 4096, 4096, 1000 neurons respectively. The first layer can be replaced with a convolutional layer consisting of 4096 filters, each with a size of m_1 \times m_2 \times m_3 = 512 \times 7 \times 7 resulting in a 4096 \times 1 \times 1 output, which in fact is only a 1-dimensional vector of size 4096.

The architecture of AlexNet also depicting its dimensions including the fully connected structure as its last three layers.(Image source (4))
Subsequently, the second layer can be replaced with a convolutional layer consisting of 4096 filters again, each with a size of m_1 \times m_2 \times m_3 = 4096 \times 1\times 1 resulting in a 4096 \times 1 \times 1 output once again. Ultimately, the output layer can be replaced with a convolutional layer consisting of 1000 filters, each with a size of m_1 \times m_2 \times m_3 = 4096 \times 1\times 1 resulting in a 1000 \times 1 \times 1 output, which yields the classification result of the image among 1000 classes (13).
Literature
[1] Convolutional networks and applications in vision (2010, Yann LeCun, Koray Kavukcuoglu and Clement Farabet)
[2] What is the best multi-stage architecture for object recognition? (2009, Kevin Jarrett, Koray Kavukcuoglu, Marc'Aurelio Ranzato and Yann LeCun)
[3] Rectified Linear Units Improve Restricted Boltzmann Machines (2010, Vinod Nair and Geoffrey E. Hinton)
[4] ImageNet Classification with Deep Convolutional Neural Networks (2012, Alex Krizhevsky, Ilya Sutskever and Geoffrey E. Hinton)
[5] Going Deeper with Convolutions (2015, Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet et al.)
[6] Deep Sparse Rectifier Neural Networks (2011, Xavier Glorot, Antoine Bordes and Yoshua Bengio)
[7] The CIFAR-10 dataset (2014, Alex Krizhevsky, Vinod Nair and Geoffrey E. Hinton)
[8] Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification (2015, Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun)
[9] Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition (2010, Dominik Scherer, Andreas Mueller and Sven Behnke)
[10] Fractional Max-Pooling (2014, Benjamin Graham)
[11] Striving for Simplicity: The All Convolutional Net (2014, Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox and Martin Riedmiller)
Weblinks
[12] http://ufldl.stanford.edu/tutorial/supervised/Pooling/ (Last visited: 21.01.2017)
[13] http://cs231n.github.io/convolutional-networks/#fc/ (Last visited: 21.01.2017)
[14] https://www.facebook.com/yann.lecun/posts/10152820758292143 (Last visited: 21.01.2017)
[15] http://iamaaditya.github.io/2016/03/one-by-one-convolution/ (Last visited: 21.01.2017)
3 Kommentare
Unbekannter Benutzer (ga29mit) sagt:
25. Januar 2017All the comments are SUGGESTIONS and are obviously highly subjective!
Form comments:
Wording comments:
Corrections:
image and mapping their appearance to a feature map
image and map their appearance to a feature map
neuronal network
neural network
can be (and in many cases(1) including AlexNet(4) and GoogLeNet(5) is)
can be (and in many cases(1) including AlexNet(4) and GoogLeNet(5) are)
Even though the general simplicity of the operation, it plays a key role in the performance
Regardless of the general simplicity of the operation, it plays a key role in the performance
Therefore the rectification is named as a "crucial component" (2).
Confusion:
Individual fully connected layers function identically (???) to the layers of the multilayer perceptron with the only exception being the input layer. (a verb is missing here)
Final remark:
Unbekannter Benutzer (ga69taq) sagt:
26. Januar 2017Thank you very much for the amazing contribution in such short time. I agree with almost all of your comments and they will be fixed, some points though i am unsure which way would work better so i would like to share them with you:
Form comments:
Wording comments:
Confusion:
Individual fully connected layers function identically (???) to the layers of the multilayer perceptron with the only exception being the input layer. (a verb is missing here): "Function" is the verb in that sentence not the name, as in "to function". I will switch the wording to "operate" in order to avoid confusion.
Everything else i agree and now have on my to do list. Again thank your very much for such a thorough and fast review. The largest problem is that now i'm under pressure that my reviews for other people will not be even half as thorough as yours .
.
As a last remark, when you select a text on viewing mode (i.e., not editing mode) a small message bubble appears which you can use to add inline comment to the page which i believe is extremely useful for reviewing.
Martin Knoche sagt:
31. Januar 2017Hi, first of all, it is really hard to find some suggestions as the second reviewer!
Regarding the language It sounds very good for me. I didn´t find any passage which I could correct or misunderstand.
The only thing I would suggest on your article is, that you could mention that there exist more Layers than all the Layers you mentioned. Like for example, DropOut Layer or BatchNormalization Layers. This is just a suggestion, but in my oppinion this will help beginners. They will see that this article is about the common layers but there will be more layers existing in common toolkits. You can also link these two other layers to the sections in the advanced level.
All in all a very good article!