1 Introduction
1.1 Problem Statement
Image Understanding includes tasks such as Image Classification or Semantic Segmentation and within the medical field these are usually used to do diagnosis prediction, treatment planning or similar. But there are factors that limit the accuracy of supervised models for theses tasks. One is that annotated data in the medical field is rare. Physicians and Radiologist are usually fully occupied with their works so there is not a lot of time to label data [1]. But vast amounts of data are necessary in supervised learning methods to achieve acceptable accuracy in the learned models. Now with the lack of data these models are often dependent on fine-tuning weights from ImageNet pretraining [1]. However, the difference between those images and imaging data is too big resulting in bad accuracy for the models. Multiple contrastive image-only learning methods such as SimCLR [6] and MoCo [7] try to overcome the lack of data and are aleady achieving great results, but due to the high-inter class similarity in medical images still the accuracy of those models is not sufficient. Hence, in this post contrastive image-language learning methods will be presented and compared to other state-of-the-art methods in different applications tasks including Image Classification, Retrieval, Segmentation, Detection and Report Generation.
1.2 Contrastive Learning
Contrastive learning is a self-supervised learning method of training a model to learn the relationship between the input pair. The process of contrastive learning is presenting the model input pairs, e.g., two images. Each of those will be encoded in a corresponding encoder to achieve a vector representation. These vector representations are then trained on a contrastive loss usually using cosine similarity. The objective is to minimize the difference between positive pairs (images that belong together e.g., both images of cats) and maximize the difference between negative pairs (images that do not belong together e.g., image of cat and image of dog). By minimizing the cosine similarity, the system maximally preserves the mutual information between positive pairs.
Now for contrastive image-language learning the input consists of a image-text pair, in the medical application this would for example be an x-ray image with corresponding report from a radiologist. Since we are now working with two different input modalities, we have a bidirectional objective. Hence, we need two contrastive loss functions one for image-to-text and one for text-to-image. The final training loss can then be computed with the weighted combination of these two losses average over all positive image-text pairs for each minibatch [1].

Figure 1: ConVIRT architecture
2 Applications
Medical Image Understanding includes multiple different downstream tasks, such as Image Classification, Semantic Segmentation or Object Detection. In the following different tasks were selected to show the effectiveness of contrastive image-language learning.
2.1 Image Classifcation, Retrieval
ConVIRT (”Contrastive Visual Image Representation Learning from Text”) is a framework that learns visual representations from pairs of imaging data with corresponding reports [1]. The weights from the trained image-encoder function are then transferred to downstream tasks such as image classification and image retrieval. For pretraining two different datasets were used: for a chest image encoder, CheXpert was used and for bone image encoder dataset from Rhode Island Hospital. For evaluation they put a linear classifier on top of the pretrained image encoder. For evaluation of the quality of visual representation, only the linear classifier was fine-tuned, for estimation how the weights are used in practical applications both pretrained weights and linear classifier where fine-tuned. Both settings were applied on four different classification tasks:
- RSNA Pneumonia Detection, a binary classification that classifies if Pneumonia exist on chest radiograph image [2]
- CheXpert image classification, a multi-label binary classification of chest images for fixed individual labels [3]
- COVIDx, binary classification of chest images if Covid or not [4]
- MURA, binary classification for bone abnormality detection, classifying into abnormal or normal [5]
They trained each using 1%, 10% and 100% of the mentioned dataset. The results were compared to the results of general initialization methods (ImageNet, Random Init) and in-domain initialization methods (Caption-Transformer, Caption-LSTM and Contrastive-Binary-Loss).
Overall ConVIRT outperforms almost on all training datasets or at least has comparable results to other initialization methods (see Figure 2). For all datasets ConVIRT outperforms ImageNet initialization. It also shows high potential for data efficiency: ConVIRT trained on only 1% training data outperforms other methods trained on 100% training data in three out of four tasks for the linear classification setting, indicating an efficient and high-quality representation learning. Like fine-tuned setting, ConVIRT trained on 10% labeled data achieves better or close results to ImageNet with 100% data usage.

Figure 2: Results for ConVIRT image classifcation
For the task of zero-shot retrieval, evaluation has been done on image-image retrieval as well as text-image retrieval. The goal for these zero-shot retrievals is to retrieve images that belong to the specific category by using a query image or query text. For image-image retrieval they encode a query image as well as candidate images with the learned image encoder. Then by ranking the similarity between those encodings the candidate images with the highest similarity are retrieved. For text-image the retrieval procedure is similar but instead of a query image it works with a query text that is encoded with the text encoder. Then as well the similarities between query und candidates are ranked. Both tasks are evaluated on the Precision@K metric.
Here as well ConVIRT outperforms all other initialization methods (see Figure 3). Even though Contrastive-Binary-Loss has quite satisfactory results for image-image retrieval compared to other initialization methods, it cannot compete with ConVIRT on the text-image retrieval task.

Figure 3: Results for ConVIRT zero-shot retrieval
As we can see contrastive image-language learning applied to classification task outperforms or achieves comparable results to other state-of-the-art initialization methods. Also, in comparison to contrastive image-only learning the models learned improved representations. In comparison to two contrastive image-only learning methods (SimCLR [6] and MoCo [7]), ConVIRT achieves best results on two Image classification tasks and for image-image retrieval. The saliency map in Figure 4 shows how well these methods focus on the relevant are for specific keywords. On the left we can see the classes and on the right marked with a red box each the relevant area in the image corresponding to the class. We can see ImageNet focuses on trivial things all over the image. Contrastive image-only methods already have a better focus on the relevant areas for the specific class. However, they do focus additionally on irrelevant areas. ConVIRT has the best overall focus on the relevant areas of the images.

Figure 4: saliency maps on sampled images
Another framework similar to ConVIRT is GLoRIA (“Global Local Representations for Images using Attention”) [8]. The difference to ConVIRT is the additional usage of attention weights, that are used the emphasize image sub-regions to particular words of the report. With that they are not only working with global representations (image to report) but also with local representation (word to image region). They pretrained on CheXpert dataset. For evaluation they did two classification tasks: supervised image classification, where a linear classifier on top of pretrained weights was trained, and zero-shot classification where they did not train with class labels but define classes from textual captions written by a radiologist.
Now the evaluation shows that GLoRIA performs better with the linear classifier trained with 1% of the dataset than ImageNet trained with 100% of the dataset (see Figure 5). But more importantly GLoRIA shows better results on RSNA dataset, on which GLoRIA framework was not pretrained on, than ConVIRT, indicating the global-local representations to help for label-efficient classification. Zero-shot classification shows comparable results to supervised models fine-tuned with 1% training data for binary classification (RSNA dataset, see Figure 6). For CheXpert (5 classes) F1 score is better than fine-tuned models.
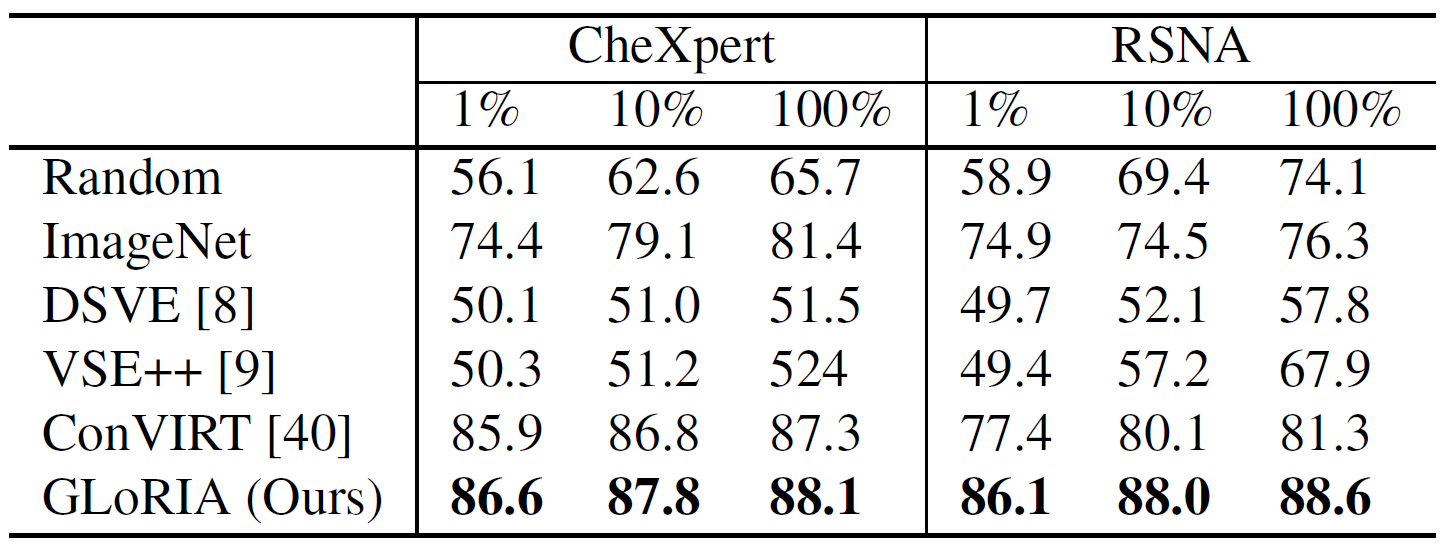
Figure 5: Results of fine-tuned image classifcation

Figure 6: zero-shot image classification on CheXpert
For retrieval task in GLoRIA they retrieved reports to a query image. Again, the query image and candidate reports are encoded each with corresponding encoder and then retrieved by ranking the similarity. Compared to ConVIRT, using GLoRIA with only global representations has almost the same results. This is as expected, since ConVIRT is only working with global representation. However, using GLoRIA with both global and local representation outperforms all other methods, indicating that additional local representations provide more needed information for a more accurate retrieval (see Figure 7).

Figure 7: Resuts of image-text retrieval on CheXpert dataset
Now the conclusions that can be drawn from these results: we can see weights pretrained with contrastive image-language learning provide a good self-supervised tool for Image Classification and Retrieval task in the medical field. No additional expert input is necessary, and we can achieve higher quality image representations with it. Especially in the comparison using only global representation to using global and local representation we can assume that the combination of both provide complementary semantic information. Also, the additional usage of local representations in GLoRIA indicates that it works better at capturing subtle visual features which is essential in medical images that have high inter-class similarities. Lastly, it has a great data efficiency: we can achieve same level of accuracy as supervised models with less training data.
2.2 Semantic Segmentation, Object Detection
In the application field of semantic segmentation, contrastive learning is again used as pre-training method and the actual segmentation part is on top of the pretrained encoder. In 2021 Shih-Cheng Huang, et al. published a paper comparing different initialization methods for 18 localized tasks such as semantic segmentation and object detection [9]. For contrastive image-language learning methods they chose ConVIRT and CLIP [10]. For better comparison they adapted CLIP to use the same image and text encoder as ConVIRT, however CLIP uses attention pooling instead of the global average pooling layer of ResNet50 to compute the image representations for the loss. They compared the results to three contrastive image-image learning methods as well as two supervised methods (trained with ImageNet and CheXpert). The contrastive learning initialization methods have all been pretrained on the MIMIC-CXR dataset, using 30% and 100% of the dataset.
The results show that all contrastive learning methods outperform Random and supervised initialization methods in dice value for semantic segmentation tasks. Additionally, using 100% of pretraining data for contrastive image-language learning initialization outperforms contrastive image-only learning initialization and perform similar with 30% pretraining data compared to image-only on 100% pretraining data (see Figure 8, SIIM-ACR Pneumothorax). The earlier mentioned GLoRIA architecture was also evaluated on the task of segmentation. Here the U-Net architecture was adapted by replacing the encoder part with the pretrained weights of the image encoder. The evaluation for this setup also showed that the learned representations are effective for segmentation. Only ImageNet trained on 100% training data performs better, however only with small margin.
For the task of object detection ConVIRT and CLIP both performed best on linear tasks outperforming all other methods. For the frozen evaluation protocol, they still perform well comparing to the other methods (see Figure 8, for RSNA Pneumonia). Hence, contrastive image-language learning still offers advantages if annotated data is not available.
In Summary, there is no single best pre-training method for all localized tasks. Contrastive image-only learning offers a good baseline as initialization method but if text is available contrastive image-language learning should be preferred, to either boost performance or reach similar performance of state-of-the-art methods with less pretraining data.

Figure 8: RSNA Pneumonia: Object Detection Results, SIIM-ACR Pneumothorax: Segmentation Results
2.3 Report Generation
The task of report generation is to create a report in natural language to an input image that describes the image findings and impressions such as a radiologist would do.
For that Tanwani, Barral and Freedman propose RepsNet, an encoder-decoder model that formulates the report generation task as a visual question answering procedure [11]. The model gets an image as well as a question as input and based on these creates either a categorical or natural language descriptive answer (see Figure 9). The workflow for this is as follows: The input image is put through an image encoder and the question through a text encoder. Both resulting representations are then fused together with a bilinear attention network. The corresponding report is also put through the same text encoder as the question. The fused representation of question and image is then contrastively learned with the representation of the report. This pre-trained image-language model is then used to interpret the images and generate automated reports in natural language.
Now in comparison RepsNet outperforms competing methods across all datasets. It can be seen that the performance increases the most with the use of pretrained models. Looking at the BLEU scores RepsNet also performs significantly better than state-of-the-art generation methods.

Figure 9: Simple architecture outline and example output of RepsNet
Another work in the field of report generation is CXR-Repair, which uses Contrastive Language-Image pretraining CLIP [12][10]. The pretrained CLIP model is trained on pairs of chest-X-ray images and corresponding reports to rank the similarity between test dataset and a large corpus of reports. The problem is framed as a retrieval task, with the thought that there is a limited amount of possible findings and diagnosis in reports, so it is possible to just choose from a big pool instead of generating language. The workflow for CXR-Repair is as follows:
- Reports or report sentences from a large corpus are passed through the pretrained text encoder
- The input chest x-ray is passed through the pretrained image encoder
- The prediction is made by selecting the report that maximizes the similarity between the text and image representations.
Evaluation results show the model is prone to repeating information due to the sentences selections process depending only on the maximizing scoring function. With that it is more likely to choose sentences that have similar content. Also, if the image has no findings the F1 reduces for the increase of number of sentences. This is due to the model trying to fill up the sentences count and possibly adding incorrect information to reach the sentence count. Still, choosing sentences from reports performs better than choosing whole reports.

Figure 10: CXR-RePaiR setup
In summary using contrastive image-language learning boost the performance of Visual Question Answering and Natural Language Generation tasks. The transferable representation learning is powerful for generating accurate and clear reports and provides state-of-the-art results for report generation. It proves to offer a good baseline for further improvement.
3 Review
The application of contrastive image-language models in the selected medical image understanding tasks show an effective tool to boost the performance and also outperform state-of-the-art models. The shown results indicate that the corresponding text gives important context which provides higher quality representations and also a better focus on relevant areas within the image. Additionally, contrastive image-language learning has a high data efficiency. It achieves results similar to supervised models using way less data and especially if annotated data is rare or not available this proves to be effective to still achieve acceptable results. Lastly, it shows efficient use of multi-modal data and implies the improvement of models by using multi-modal input training data.
4 Personal Review
Contrastive image-language learning seems to be a beneficial method for multiple reason. Of course, for application fields that lack annotated data it offers a great method to achieve models with good accuracy results. However, more importantly it proves to be a method that utilizes the corresponding texts well and with that improving image understanding tasks. Considering supervised methods, the model learns the relationship of simple labels to whole images. But pathologies might be more complicated than that. By using longer texts describing the image in more detail than with labels and learning them contrastively with corresponding images, the model is able to connect specific keywords in the text to specific areas in the image, making it understand the image in more detail than just connecting it to one class label. I think the featured papers in this blogpost show that contrastive image-language learning has already proven to be a state-of-the-art initialization method for medical image understanding and should be further researched and improved.
5 References
[1] Zhang, Yuhao et al. (2020). Contrastive Learning of Medical Visual Representations from Paired Images and Text.
[2] Xiaosong Wang et al. (2017) ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised
classification and localization of common thorax diseases.
[3] Jeremy Irvin et al. (2019) CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison
[4] Linda Wang and Alexander Wong. (2020) COVID-Net: A tailored deep convolutional neural network design for detection
of COVID-19 cases from chest X-ray images.
[5] Pranav Rajpurkar et al. (2018) MURA: Large dataset for abnormality detection in musculoskeletal radiographs.
[6] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Georey Hinton. (2020a) A simple framework for contrastive learning of visual representations.
[7] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. (2020b) Improved baselines with momentum contrastive learning.
[8] Huang, Shih-Cheng & Shen, Liyue & Lungren, Matthew & Yeung, Serena. (2021). GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-efficient Medical Image Recognition.
[9] Müller, Philip & Kaissis, Georgios & Zou, Congyu & Rueckert, Daniel. (2022). Radiological Reports Improve Pre-training for Localized Imaging Tasks on Chest X-Rays.
[10] Radford, Alec & Kim, Jong & Hallacy, Chris & Ramesh, Aditya & Goh, Gabriel & Agarwal, Sandhini & Sastry, Girish & Askell, Amanda & Mishkin, Pamela & Clark, Jack & Krueger, Gretchen & Sutskever, Ilya. (2021). Learning Transferable Visual Models From Natural Language Supervision.
[11] Tanwani, Ajay & Barral, Joelle & Freedman, Daniel. (2022). RepsNet: Combining Vision with Language for Automated Medical Reports.
[12] Endo, M., Krishnan, R., Krishna, V., Ng, A.Y. & Rajpurkar, P.. (2021). Retrieval-Based Chest X-Ray Report Generation Using a Pre-trained Contrastive Language-Image Model.