1. Introduction
Recent advances in generative models have produced impressive results in creating high-quality synthetic images [1, 2]. However, these models frequently struggle to integrate multiple complex concepts or to generate outputs for several modalities [3]. These limitations reduce their ability to create complex visual representations required for real-world scenarios.
This is especially interesting in the medical field, where it is crucial to seamlessly combine information from various imaging techniques, including computer tomography (CT), magnetic resonance imaging (MRI), and X-rays, for patient treatment. Every modality provides unique information, and combining and interpreting these sources is vital for accurate decision-making. Additionally, improvement of the capabilities of future models can be reached by using generative models to create new samples for datasets of scarce medical conditions and data pairs of multiple modalities.
2. Background
2.1. Diffusion Model
Diffusion models [4] are generative models based on the concept of physical thermodynamics, which defines the diffusion process as the movement of particles from high to low concentration until they reach an equilibrium state. In a generative diffusion model, this forward diffusion process is simulated by gradually introducing a small amount of Gaussian noise to a sample at T steps. As T gets bigger, the sample loses its distinct features and eventually converges to a Gaussian distribution.
The model aims to learn the backward diffusion process, which tries to reverse the process of adding noise and returns a result that approximates the target distribution. This makes the model capable of constructing a new sample from Gaussian noise.
Denoising Diffusion Probabilistic Models (DDPM)
DDPMs [11] are a class of generative models that leverage the above-mentioned diffusion process. The core idea is to progressively add noise to data in a forward process and learn to reverse this process.
Forward Diffusion Process: Noise is added to the data over a series of time steps, which can be described by the following equation:
| q(x_t|x_{t-1}) = N(x_t;\sqrt{1-\beta_t}x_{t-1}, \beta_t I) |
where $x_0$ is the origin data, $x_t$ data at the time step $t$ , and $\beta_t$ a variance schedule that controls the amount of added noise in each step. The forward process can also be written as a Markov chain:
| q(x_{1:T}|x_0) = \prod_{t=1}^T q(x_t|x_{t-1}) |
Reverse Diffusion Process: The goal is to denoise the data, this is achieved by learning a neural network to approximate the reverse conditional distribution:
| p_\theta(x_{t-1}|x_t) = N(x_{t-1}; \mu_\theta(x_t, t), \sum_\theta(x_t,t)) |
where $\mu_\theta$ and $\sum_\theta$ are the mean and variance predicted by the neural network parameterized by $\theta$ .
3. Related Papers
3.1. Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models [5]
Problem Statement
In this paper, Kwon et al. present a model to generate coherent images that precisely fuse several user-specified concepts into a single output image. Conventional methods frequently struggle to maintain the distinct characteristics of each concept or require a joint training phase. Concept Weaver introduces a method that allows the fusion of multiple custom concepts at inference time. The result is a model that generates images not only by the semantic meaning of the input prompt but also by retaining the distinct visual features of each concept. In this context, a concept is defined by a specific set of images of any subject or object (e.g. a dog or a mountain).
Method
The core innovation of Concept Weaver is the concept fusion strategy, which enables the integration of multiple custom concepts into a template image while preserving the structural and semantic alignment of the input prompt. Generally, it is based on two consecutive steps: first, a template is created which is aligned with the input text prompt; second this template is personalized by fusing the appearances of the target concepts into the template. A full overview of the process can be seen in Figure 1.

In the beginning, a Custom Diffusion [6] model is fine-tuned for each concept with the following loss function:
| \mathbb{E}_{\epsilon,x,p,t}[|\epsilon -\ \epsilon_{\theta}(x_t,p,t)|] |
\epsilon_\theta is the denoising network, \epsilon is sample Gaussian noise, t are the time steps, and p is the text condition. The fine-tuning only affects the key and value parameters in the cross-attention layers, the rest of the network remains fixed. Every concept prompt also includes a modifier token, which prevents the model from altering the general concept and directs it toward learning the specific visual traits of the provided examples.
The next step is to generate a template image with the input prompts. This is done by using a pre-trained diffusion model, in this case Stable Diffusion [7]. To preserve the structural details of the template image during the fusion process, the authors perform an inversion. Specifically, they perform a forward pass through the pre-trained DDIM to generate a noisy latent representation of the template image. From the fully inverted noise, the original template image is reconstructed during the backward pass of the diffusion model. During this reconstruction, certain feature outputs of the U-net are extracted. These extracted features capture important spatial and structural information of the template images. In the end, the multi-concept-fusion process is started. For each concept a separate fine-tuned diffusion model is used to generate an image. The starting point of the generation is the noisy latent representation and the extracted features are injected into the cross-attention layers. Finally, the individual generated images from the different models are fused together using masked guidance, allowing to fill the specific regions of the image with the corresponding concept.
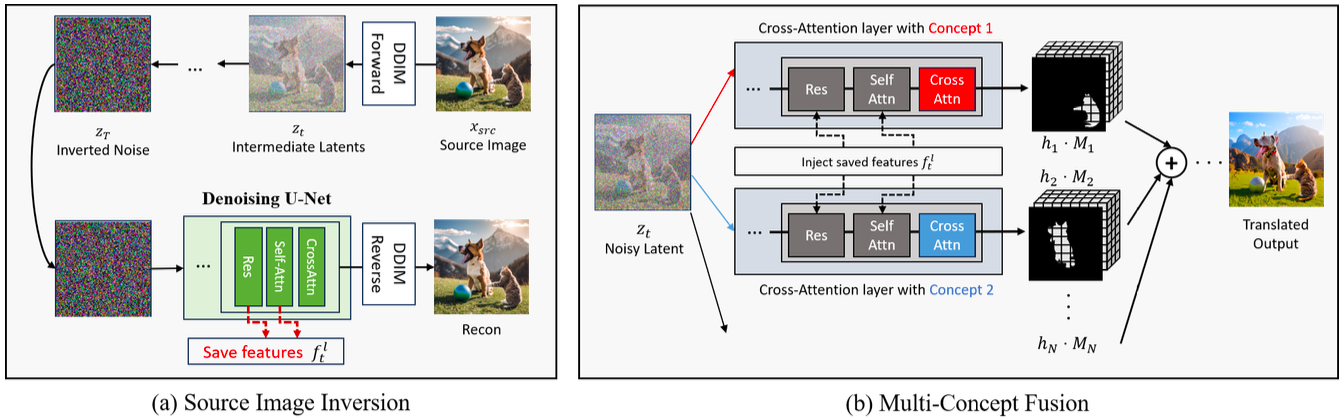
Results
The authors extensively evaluated the performance of Concept Weaver across various metrics and baseline models and examined the impact of the different design choices. The presented results conclude that Concept Weaver performs better when applying multiple concepts with complex interactions between them than current state-of-the-art models.
The qualitative evaluation (Figure 3) shows that the model successfully maintains the style of the target concept.

Additionally, it is interesting to see the detailed generation output, which includes the original image, the mask, and the combined image (Figure 4). It is obvious that using an exact mask allows the method to combine interactions without mixing concepts.

3.2. Instruct-Imagen: Image Generation with Multi-Modal Instruction [3]
Problem Statement
The proposed Instruct-Imagen model introduced by Hu et al. aims to solve the following problems in image generation:
- Limited integration of multi-modal information: existing models primarily focus on specific input modalities like text prompts or edges.
- Inability to generalize to unseen tasks: most of the current models struggle to generalize to unseen tasks that deviate from the training data or when combining multiple concepts in one image.
Method
Instruct-Imagen uses a two-stage cascaded diffusion model architecture adapted from the Imagen [2] model. The full architecture can be seen in Figure 5. The first stage is a text-to-image generation model that produces lower-resolution images. In the second stage, a super-resolution model is applied, which up-samples the images to higher resolutions.

The main improvements are modifying the text-to-image model, that now incorporates multi-modal instruction, and improving the training process. Multi-model instructions are supported by adding an additional cross-attention layer that conditions the bottleneck representation of the network on the embedded multi-modal context. In addition, the down-sampling network is used as an encoder to extract latent features from the given multi-modal instructions, which can include text or other modalities such as edges, styles, and subjects. The extracted features are then integrated into the text-to-image model via cross-attention layers.
The training procedure is divided into two phases, visualized in Figure 6. First, the pre-trained text-to-image diffusion model is trained on a newly created dataset. The dataset consists of domain-specific clustered image-text pairs with five pairs per cluster. During training, one pair was selected as the input and target for the model and three other pairs as the multi-modal context. This phase is called retrieval-augmented training, and its impact is shown in Table 1 in the result section. The second phase fine-tunes the model on a diverse set of image generation tasks focused on multi-modal instructions. This includes tasks that combine text with other modalities as mentioned above.

Results
Instruct-Imagen was tested on in-domain and zero-shot problems, where the latter involves of complex and unseen instructions for image generation. The evaluation was performed using a variety of datasets and was evaluated by human based on semantic consistency and perceptual quality. The full results compared to different models can be seen in Figure 7. The single-task and multi-task models are baseline models of Instruct-Imagen with the same model architecture, but they do not have access to multi-modal instruction during fine-tuning. Instead, they directly accept the raw multi-modal inputs relevant to the specific task.

Additionally, the authors also tested the importance of retrieval-augmented training, which shows significant model improvements in both in-domain and zero-shot evaluations (Table X).

3.3. MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant [8]
Problem Statement
The MedM2G framework was proposed by Zhan et al. and addresses the lack of a unified framework that can effectively align and generate multiple medical modalities while preserving the unique visual invariant information for each imaging modality.
Recent methods for medical image generation models have significantly improved [9,10]. However, every modality is treated individually, resulting in inefficient analysis. For multi-modality, conventional methods often struggle to align and integrate diverse medical generation tasks, leading to a mix of information of different modalities. The lack of a large and diverse medical datasets over multiple modalities further hinders development and training of effective multi-modal generation models.
Method
The authors introduce a framework to unify various medical multi-modal generation tasks within a single model. In the beginning, each modality is encoded in its respective latent space. A crucial step is to align the different medical modalities into a shared latent space. They use the text-model for the alignment of the latent space, as it is included in most datasets. The central alignment is accomplished by using the following loss function:
| L_{A,B} = - log(\frac{exp((z_i^A)^T z^B_i / \tau)}{ exp((z^A_i)^T z^B_i / \tau) + \sum_{j\neq i} exp((z^A_i)^T z^B_j / \tau) } |
where $\tau$ regulates the SoftMax distribution, $j$ refers to negative samples, z^A_i is the embedding of a medical feature from a modality A with the text encoder, and z^B_i is the embedding of a medical feature from all other modalities B with their respective encoder.
Another important feature of MedM2G is the preservation of the medical visual invariant for each imaging modal to maintain the unique clinical properties and diagnostic values. This is achieved by minimizing the off-diagonal elements of the cross-correlation matrix of two augmented images from the dataset.
The framework also introduces a novel latent cross-guided alignment generation approach to enable flexible interaction among medical modalities. Guided adaption extracts features from the latent representation of one modality and processes them for another modality. This includes sampling relevant features, embedding them and projecting them to unified shared latent space using a context encoder. Subsequently, cross-conditioning leverages the extracted features from the source modality to condition the target modality’s generation process. This allows the model to effectively integrate information from different modalities, enabling the generation of coherent and clinically relevant outputs.
These components are combined in three rounds of multi-flow training. Each round focuses on a specific cross-guided alignment task: Text-X-ray, Text-CT, CT-MRI. To ensure efficient training and knowledge transfer, the modality-specific encoders are trained one at a time and then frozen (see Figure 8).

The datasets used for training MedM2G span over the supported modalities, including text reports, CT scans, MRI images, and X-rays. To address the limited medical cross-modal datasets, the authors generate paired data for different modalities.
Results
The MedM2G framework demonstrates state-of-the-art performance across various medical multi-modal generation tasks and datasets, consistently outperforming existing methods.
MedM2G presents its multi-modal capabilities qualitatively and is evaluated quantitatively on the following subtask:
- Text-to-image generation: generate medical images (CT, MRI, X-ray) from text descriptions
- Image-to-text generation: generate medical reports from images
- MRI-CT Translation: generate CT scans from MRI images
- Chest X-ray generation: generate chest X-rays from text
MedM2G achieves state-of-the-art results on all medical multi-modal generation task, as seen in the following Tables 2, 3, 4.



4. Conclusion
This blog post introduces three different approaches for multi-modal generative models. The aim of the papers is to enhance these models flexibility and personalization capabilities by leveraging diffusion models and introducing novel techniques to improve the integration of multiple modalities or concepts.
Concept Weaver focuses on enabling the fusion of multiple concepts in text-to-image models, making it relevant for applications requiring the combination of personalized concepts and customization of real images. It uses a two-step process of template creation and concept fusion to achieve good evaluation scores in such tasks and maintains the distinct characteristics of each concept very well. The limitations of this method is that it requires a separate fine-tuned model for every new concept, which is computationally expensive and limits its applicability in real-time scenarios. This model could be used in the medical field to create comprehensive visualizations for complex diagnoses by combining features from various scan modalities (MRI and CT).
Next, Instruct-Imagen proposes a method to generalize image generation across various domains by utilizing multi-modal instructions to manage diverse tasks. This method also shows promising results in zero-shot problems, which are tasks that were not included in the training set. Multi-modal instructions and retrieval-augmented training are used to achieve this performance. Instruct-Imagen has fast inference times and well documented implementation details. However, the cascaded diffusion models can introduce artifacts when upscaling to a higher resolution. A possible limitation of retrieval-augmented training is that it can introduce biases based on the retrieved data, which could affect the fairness and accuracy of the model's output. Instruct-Imagen's capabilities makes it a potentially useful tool for developing visual aids for patient education. In order to assist patients in understanding medical procedures or conditions, it could be used to create personalized images based on textual descriptions and other visual inputs.
MedM2G is designed for medical applications and combines several medical imaging modalities to improve diagnostic capabilities and creation of new medical multimodal data. The authors introduce a multi-flow cross-guided diffusion strategy with adaptive parameters, that focuses on preserving medical visual invariants in its generation tasks. MedM2G is extensively evaluated against prior single-task models, demonstrating its effectiveness in its tasks. Nevertheless, it’s more complex to read the paper, as the referenced appendix containing supplementary implementation details and results is missing. The report-generation of the model is also limited and may not provide a complete diagnostic picture for complex medical cases, as the model is only able to take one input image.
All papers present novel techniques, but as mentioned above, they are not without limitations. Furthermore, the authors of all three publications have not yet made their code repositories public, at the time of writing this blog post, which makes it more difficult to replicate these techniques and conduct additional research on them.
5. References
[1] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis With Latent Diffusion Models,” presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10684–10695. Available: https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html
[2] C. Saharia et al., “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding.” arXiv, May 23, 2022. doi: 10.48550/arXiv.2205.11487.
[3] H. Hu, K. Chan, Y. Su, W. Chen, Y. Li, K. Sohn, Y. Zhao, X. Ben, B. Gong, W. Cohen, M. Chang, X. Jia, “Instruct-Imagen: Image Generation with Multi-modal Instruction.” arXiv, Jan. 03, 2024. Available: http://arxiv.org/abs/2401.01952
[4] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep Unsupervised Learning using Nonequilibrium Thermodynamics,” in Proceedings of the 32nd International Conference on Machine Learning, PMLR, Jun. 2015, pp. 2256–2265. Available: https://proceedings.mlr.press/v37/sohl-dickstein15.html
[5] G. Kwon, S. Jenni, D. Li, J.-Y. Lee, J. C. Ye, and F. C. Heilbron, “Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models.” arXiv, Apr. 05, 2024. Available: http://arxiv.org/abs/2404.03913
[6] N. Kumari, B. Zhang, R. Zhang, E. Shechtman, and J.-Y. Zhu, “Multi-Concept Customization of Text-to-Image Diffusion.” arXiv, Jun. 20, 2023. doi: 10.48550/arXiv.2212.04488.
[7] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models.” arXiv, Apr. 13, 2022. Available: http://arxiv.org/abs/2112.10752
[8] C. Zhan, Y. Lin, G. Wang, H. Wang, and J. Wu, “MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant.” arXiv, Mar. 07, 2024. Available: http://arxiv.org/abs/2403.04290
[9] B. Segal, D. M. Rubin, G. Rubin, and A. Pantanowitz, “Evaluating the Clinical Realism of Synthetic Chest X-Rays Generated Using Progressively Growing GANs,” SN COMPUT. SCI., vol. 2, no. 4, p. 321, Jun. 2021, doi: 10.1007/s42979-021-00720-7.
[10] M. Özbey et al., “Unsupervised Medical Image Translation With Adversarial Diffusion Models,” IEEE Trans. Med. Imaging, vol. 42, no. 12, pp. 3524–3539, Dec. 2023, doi: 10.1109/TMI.2023.3290149.
[11] J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models.” arXiv, Dec. 16, 2020. Available: http://arxiv.org/abs/2006.11239