Medical image fusion is the process of registering and combining multiple images form single or multiple imaging modalities to improve the imaging quality and reduce randomness and redundancy in order to increase the clinical applicability of medical images for diagnosis and assessment of medical problems. [1]
In general, the aim of image fusion is to construct a more detailed and representative output image. In order to achieve such goal, the following steps are required.
- Image Registration: It is the process of mapping the input images with the help of a reference image, i.e. to match the corresponding images based on certain features. This step is considered as a optimisation problem, where we want to maximise a similarity measure and/or minimise the cost. A parametric transformation Tg() is applied to the input or target images It in order to maximise the similarity with the reference image Ir.
- Feature Extraction: The characteristic features of the registered images are extracted and for each input images, one or more feature maps are produced.
- Decision Labelling: Based on a given criteria, a set of decision maps are produced through applying a decision operator that aims to label the registered images' pixels or the feature maps.
- Semantic Equivalence: In some cases, the obtained features or decision maps might not refer to the same object or phenomena. In these cases, semantic equivalence is applied in order to link these maps to common objects or phenomena to facilitate the fusion procedure.This step is very important for the inputs from the same type of sensors.
- Radiometric Calibration: The spatially aligned input images and feature maps are transformed to a single scale, resulting in a common representation format.
- Image fusion: This is the last step and the aim is to combine the resulting images into a single output image containing a better description of the scene. The final benefits include:
- Better quality of the information
- Extended range of operations
- Extended spatial and temporal coverage
- Reduced uncertainty
- Increases reliability
- Robust performance
- More compact representation of the information
In the following images, it can be seen different fusion images resulting from different modalities.

From left to right. MRI T1 (up) MRI T2 + Gd (down), PET, MRI T1 - PET (up) and MRI T2 + Gd - PET (down) [3]


Image Registration Methods
Image registration is the most important and complex step of the image fusion process. There are several ways to register the data, the methods classification might vary depending on the classification criteria we are using. In this page they will be classified according to the nature of registration.
- Extrinsic:
- Invasive
- Non Invasive
- Intrinsic:
- Landmark based.
- Segmentation based.
- Voxel property based.
- Non-Image based
- Others:
Extrinsic Registration Methods
This type of registration is based on foreign objects introduced into the image space. The methods it includes rely on artificial objects attached to the patient, designed to be well visible and detectable in all the pertinent modalities. Therefore, the registration of those images is easy, fast, can be automated and there is no need for complex optimisation algorithms as the registration parameters can often be computed explicitly. However, the main drawbacks are the invasiveness and that provisions must be made in the pre-acquisition phase.
There are mainly two types of foreign objects used for extrinsic registration:
- Stereotactic frame: it is screwed to the patient's outer skull table. This device is considered the "gold standard" for registration accuracy. The frame is used for localisation and guidance purposes in neurosurgery. It doesn't add an additional invasive strain to the patient but the mounting og a frame only for registration purposes is not permissible.
- Fiducial (screw markers): the most popular of these markers are the ones that are glued to the skin.


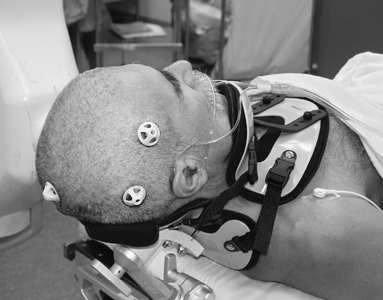
Intrinsic Registration Methods
These methods rely only on patient generated image content. The registration can be made in mainly three different ways:
- Landmark based: The registration uses a limited set of identified salient points, i.e. landmarks. They can be anatomical, usually identified by the user, or geometrical landmarks, such as corners. This technique is quite versatile as it can be applied to any image, no matter what the object or subject is. Landmark based methods are commonly used to find rigid and affine transformations. They can also be used in combination with other registration methods that are based on a optimization process and may get stuck in local optima. Landmarks constrain the search space and the mismatches are less likely to occur. However, the main drawback is the a user interaction is usually required in order to identify the landmarks.
- Segmentation based: They can be rigid, where same anatomically structures are extracted for both the target and the reference image and used an input for the alignment process, or deformable, where a structure is extracted from one image and elastically deformed to fit the second image.
The rigid approaches are the most used of the segmentation based registration methods. This is mainly due to the "head hat" method introduced by Pelizzari [9], which relies on the segmentation of the skin surface in CT, MRI and PET images. To learn more about this technique, please click here. The main drawback of these methods, is that the registration accuracy is limited to the accuracy of the segmentation step. The areas where they are most commonly used are neuro- and orthopedic imaging. The segmentation step is usually automated. - Voxel property based: The difference between this group of methods and the previously defined, is that they operate directly on the image grey values, without prior data reduction by the used or segmentation. There are to approaches:
- To reduce the image grey value content to a representative set of scalars and orientation,
- To use the dull image content throughout the registration process.
Non-Image Based Registration Methods
This is made when the imaging coordinate systems of the two scanners involved are somehow calibrated to each other. This usually requires that the scanners are both in the same physical location, and the assumption that the patient won't move between both acquisitions. These requisites can be met in ultrasound, as the devices come as hand-held devices with a spatial localization system. They are easily calibrated and can be used while the patient is immobilized in the CT, MRI or operation room. Moreover, the development of multi-modal devices, such as an integrated CT-PET and CT-SPECT, makes possible to acquire both functional and structural data in the same session, and thus limiting the fusion accuracy problems without the need for fiducial markers and/or complex mathematical algorithms.

AnyScan® SPECT-CT-PET triple modality system [12]
Others
- Learned-based: it uses prior knowledge of the underlying registration problem in order to achieve robust and more accurate registration results.
- Biomechanical models: The sliding motion between two anatomical structures produces a discontinuous displacement field between their boundaries. Capturing the slide motion is quite challenging for intensity-based registration. Therefore they incorporate a biomechanical model with a non-rigid image registration scheme for motion estimation. This method has been applied in lung cancer patients to capture the lung deformation. [14]
Bibliography
[1] A. P. Jamesa, B. V. Dasarathyb. 2014. Medical Image Fusion: A Survey of the State of the Art.
[2] F. El-Zahraa, A. 2015. El-Gamal. Current Trends in Medical Image Registration and Fusion.
[3] http://www.medicalexpo.com/prod/hermes-medical-solutions-inc/product-100595-677505.html
[5] K. Iqbal, S. Altaf. 2015. Brain Gliomas CT-MRI Image Fusion for Accurate Delineation of Gross Tumour Volume in Three Dimensional Conformal Radiation Therapy. Source: https://www.omicsgroup.org/journals/brain-gliomas-ctmri-image-fusion-for-accurate-delineation-of-gross-tumor-volume-in-three-dimensional-conformal-radiation-therapy-2167-7964-1000184.php?aid=50834
[6] http://www.medicalexpo.com/medical-manufacturer/stereotactic-frame-1219.html
[7] http://ogles.sourceforge.net/ogles-doc/index.html
[8] https://neupsykey.com/frameless-functional-stereotactic-approaches/
[9] A.W.Toga. Brain Warping . Pages 267-271.
[10] J. B. A. Maintz, M. A. Viergever. An Overview of Medical Registration Methods. Source: http://www.iro.umontreal.ca/~sherknie/articles/medImageRegAnOverview/brussel_bvz.pdf
[11] S. Fanti. Atlas of SPECT-CT. Page 240. Source: Atlas of SPECT-CT
[12] http://www.bartectechnologies.com/anyscanmultimodal.html
[13] C.Guetter, C.Xu. Learning based non-rigid multi-modal image registration using Kullback-Leiber divergence.
Kommentar
Unbekannter Benutzer (ga39tec) sagt:
07.Juni 2017Hi,
this is a good overview of the topic. You found good images to illustrate the different processes.
Because of the importance for intraoperative imaging, I would have liked some more information on non-rigid methods to make it perfect.