A neural network or an artificial neural network (ANN) is an artificial reproduction of the biological neural system and is a programming paradigm to process information. Figure 1 shows the relations between a biological neuron and its mathematical model. The structure of ANNs is comprised of many interconnected processing elements, artificial “neurons”, which exchange information between each other to solve specific problems by detecting different features. Due to a training process connections between those neurons gain a certain numeric and learnable weight. Furthermore several “neurons” build up a layer and by stringing together a lot of those layers, whereby each layer inspects their previous layer for primitive patterns, a neural network can be created, as shown in Figure 2. A convolutional neural network (CNN) consists of up to 25 distinct layers whose neurons are built three-dimensionally (width, height, depth), as shown in Figure 3 (1)(6).
The target for this invention is that the trained network will figure out a solution on its own, it can change and improve by itself, whereas, the conventional programming solves problems by telling the computer what to do with precisely defined tasks. Due to this special feature CNNs became more and more important in the last few years, especially in terms of image and speech recognition, video analysis and computer vision. That is why large companies such as Google, Microsoft and Facebook invest in the research and development of CNNs on a large scale. The reason for CNNs to get a lot of attention and evolve in the recent years significantly is the ruggedness to shifts and distortion in the image, which means that differences in camera lenses, poses or lightning conditions will not harm the process easily. Additionally, because of convolutional layers a fewer memory is required and, on top of that, by the reduced number of parameters and therefore a reduced training time the teaching process of a CNN is better and easier. Those and other benefits of CNNs will become evident in the following chapters (1)(6).
This wiki about convolutional neural networks has been split into three main parts, the Basic, Advanced and Practice/ Implementation Level. The first will provide information for a fundamental understanding about machine learning, neural networks and most important convolutional neural networks. In the second main chapter the optimization, limiting factors and other advanced topics of CNNs will be analyzed more precisely. The Implementation Level will concentrate on examining different CNN tools and specific applications.
To get a basic knowledge for the upcoming topics, machine learning and image processing will be explained first.



Machine Learning
Machine learning (ML) stands for an artificial creation of knowledge that is generated through experience. This means the system goes through a learning phase by studying examples at first, so that it can generalize those afterwards. During the learning phase patterns and other regularities are memorized, consequently, those patterns will be discovered while inspecting new and unknown data, it is called transfer of learning (3). The beginnings of machine learning can be traced back to 1950 when Alan Turing created the “Turing Test”, in which the computer is tested if it has real intelligence by making a human believe it is also human. In 1952 the first learning program for a computer was a game of checkers which improved itself by studying moves that lead to victory. It was written by Arthur Samuel. Five years later, in 1957, the first neural network was created by Frank Rosenblatt. The intention was the simulation of the thought process of the human brain. In the 1990s programs were developed to analyze a large amount of data. 2014, Facebook introduced their software algorithm DeepFace, which is capable of recognizing and verifying objects on photos as proficient as a human. 2016, a professional player of Go, a Chinese and world’s most complex board game, was beaten by Google DeepMind’s algorithm AlphaGo. These were just a few milestones in machine learning and it keeps on evolving (7).
Those algorithms have a lot of different approaches when it comes to practical implementation and the most common ones will be explained more specifically, the supervised, unsupervised and reinforcement learning.

Supervised Learning
Supervised learning, a subfield of machine learning, is a learning process to replicate labeled regularities. Thereby, already known results and data are supposed to train the system. A network, as previously mentioned, consists of several neurons and connections between those neurons which have individual and learnable weights. A weight is parameter of a neuron that can be adjusted during the teaching phase. The procedure of a teaching is as follows:
- Determine the data set of examples which functions for the teaching process and gather a selection of data
- Processing the input and training the system with a training set of data
- Comparing the output via test set of data with a desired outcome and checking for errors by evaluating the results
- Minimizing the error by modifying the weights (parameters), e.g. backpropagation
Afterwards the program is supposed to be capable of analyzing an unknown training set and delivering the correct output. Sometimes a large number of parameters or a few amount of training material can lead to the problem named overfitting. A possible reason is that the known data and their patterns were taught separately instead of being generalized. This issue can be prevented by decreasing the number of parameters and stopping the training process at the right moment (3)(5).
The learning process of convolutional neural networks and other networks, e.g. recurrent neural networks, are allocated to the supervising approach.

Unsupervised Learning
Unsupervised learning is based on the general understanding of the data at hand. The data is unlabeled and unstructured, hence, the output cannot be foreseen. Therefore, this learning method tries to identify the patterns by deviations of unstructured noise and adapts the weights of the neurons to similarities of input values. Typical areas of application are clustering and data compression.
- Clustering: Patterns and regularities with similarities are put together in the same group. Furthermore, clustering can be used to identify new groups within the data to insert those for pattern recognition afterwards.
- Data compression: During this operation a large amount of data is reduced or compressed. Consequently, the memory is reduced and transmission time is shorten because a fast and simple model is desired.
As shown in Figure 5 and 6, with supervised learning it is known in advance that there are two categories, on the other hand, the unsupervised results in two groups. An example will provide clarification for the difference between the supervised and unsupervised approach: A large amount of movies is given. If the movies are supposed to be sorted by different characteristics, e.g. what kind of movies watches a specific age group, unsupervised learning is applied. In contrast, supervised learning divides the movies strictly into their different genres (3)(5).

Reinforcement Learning
Reinforcement learning (RL) can be compared to the learning method of humans. The system is learning autonomously to maximize its performance by getting reward or punishment feedback from the environment. This is based on the Markov decision process (MDP). In RL, the computer simply tries to achieve a given goal. The machine does not know which following step would be the best, but it receives at a certain time a reward, positive or negative, which allows to evaluate its utility (trial-and-error). A reward is scalar feedback signal that indicates how well the system is doing at a certain step and its job is to maximize the cumulative reward. An obvious limitation to this approach is the huge memory that is needed to save every value to each state of a potentially complex issue. RL approach is applicable in various fields like game theory, control theory and genetic algorithms (3)(4) .
In comparison to supervised learning where the classifier is based on known input and output data, in RL an algorithm is built only based on input data. In contrast to the strict approach to connect the input with the outcome, the RL algorithm finds its own path to its unknown output via reward and punishment feedback.

Figure 7: Simplified Model of Reinforcement Learning
Image Processing
Image processing is a way to process signals executing mathematical operations on an input, e. g. an image, a video etc., and receive as an output another image, characteristics or parameters of the analyzed input. By converting an image into digital form, it is desired to extract useful information. Basically, image processing is divided into three parts(2).
- Importing an image via image receiving tools
- Analyzing and manipulating the image, e.g. data compression, image enhancement etc.
- Output in which result can be altered image or report based on image analysis
There are two types of image processing, an analog and digital approach. Analog image processing is defined by the totality of techniques which manipulate an image via physical process. However, this wiki deals more with the digital image processing which has many different purposes, e.g. visualization, image sharpening and restoration, image retrieval, measurement of pattern and image recognition. For an image to become compatible for digital processing, a digitization, spatially and in amplitude, is done via sampling and quantization. To get originality of information from digital images, it has to undergo three general phases: pre-processing, enhancement and display, information extraction. Performing operations on a digital image by a digital system is the target of digital image processing. Defined by a function f (x, y) where x and y are determined as the horizontal and vertical axis, an image is a two-dimensional signal apparently. Well known, an image consists of many pixels, those pixel values represent a value of the function f at any point and range between 0 and 255(2).
This application is used in many various fields of science and engineering disciplines, medical diagnostics, remote sensing like environmental monitoring and even face recognition.
A very suitable method in representing adaptive image processing and forming a link between general feedforward neural networks and adaptive filters is a convolutional neural network.
For more information and a more detailed explanation the chapter Image Processing and Convolution is highly recommended.

Figure 8: A Chronological Procedure of Image Processing 
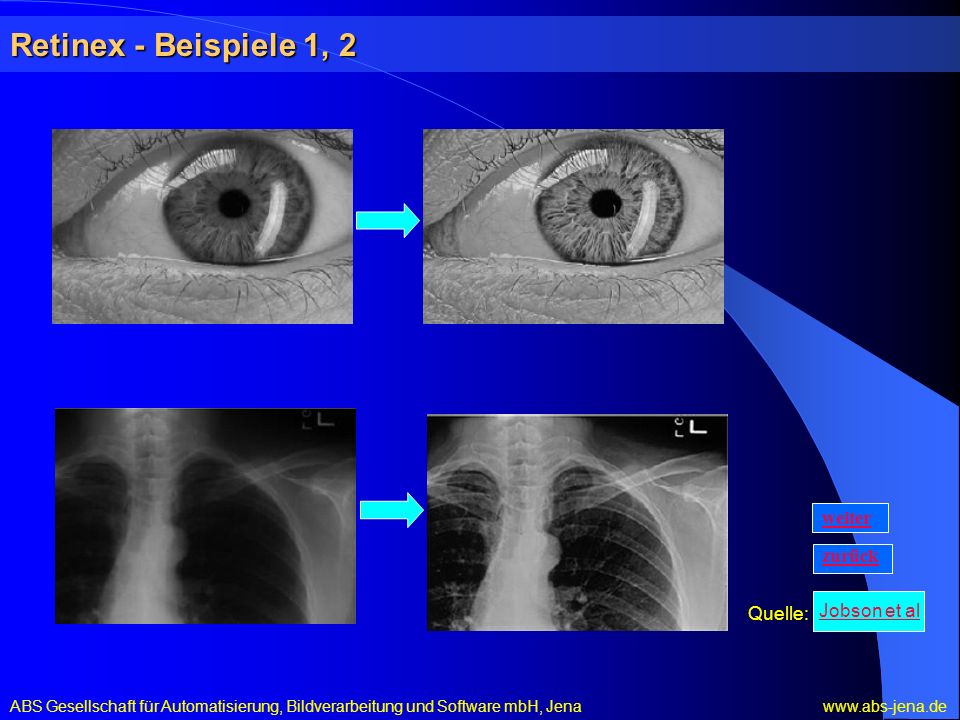
Figure 9: Comparison of Images before and after being processed Source: (link)
{kind=link}
Literature
[1] Convolutional neural networks for image processing: an application in robot vision by Matthew Browne, Saeed Shiry Ghidary, 2003
[2] Digital Image Processing - Band 1 by Bernd Jähne, 2005
[3] Machine Learning and Data Mining by Igor Kononenko, Matjaz Kukar,
[4] Reinforcement Learning by Richard S. Sutton, 2012
[5] Supervised and Unsupervised Pattern Recognition: Feature Extratraction and Computational Intelligence by Evangelia Micheli-Tzanakou, 2000
[6] Using Convolutional Neural Networks for Image Recognitionhttps://ip.cadence.com/uploads/901/cnn_wp-pdf by Samer Hijazi, Rishi Kumar, and Chris Rowen, IP Group, Cadence, 2015