Dokumentation
Closing the Gap to Real Data
Overview
Our Approach relies on generating data using domain adaptation or randomization methods as well as photo-realistic rendering. We use these datasets to train a deep learning method and compare the performance on a real dataset (see the figure below.)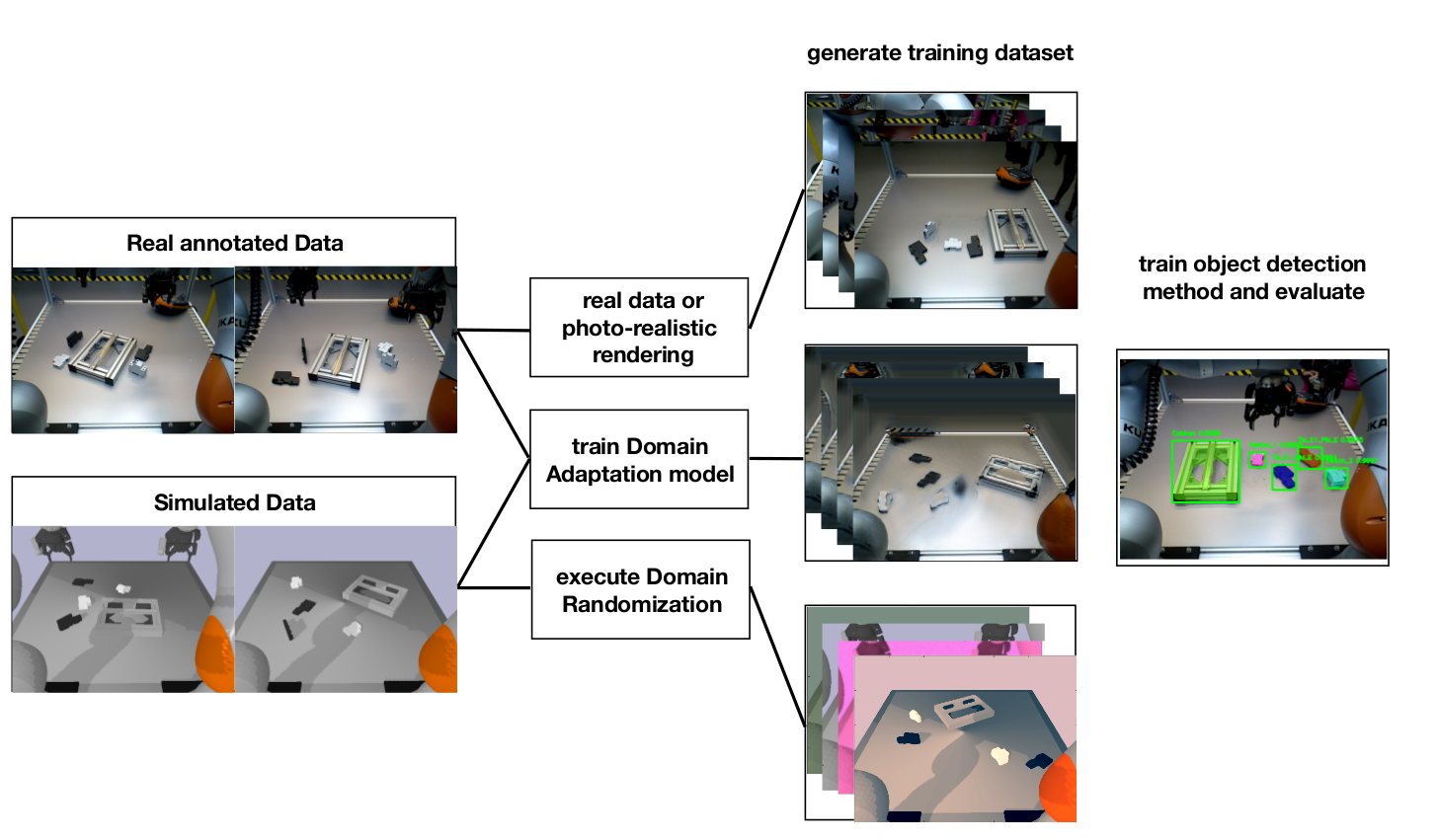
Photo-Realistic Rendering
The main idea for photo-realistic rendering is to render images that model the physics of the real world well enough, such as reflections, noise, light variations and so on. An example for a possible renderer is the Mitsuba Renderer. Mitsuba renders images slower than other simpler renderers. It is also possible to create very complicated scenes with Blender. For our experiments we use a set of real annotated images. This means we assume the best case scenario where photo-realistic rendering would render the same scene as in reality.
We also consider another case where we scan the textured models using the EinScan scanner. We place the scanned models in background images of the real scene as well to generate datasets. The figure below includes both possibilities for these kind of datasets. On the left you’ll see the real images and on the right the images with the scanned models.
|  |
|---|---|
| Real image taken from the scene | Scanned models placed with random real backgrounds |

Domain Adaptation
Domain Adaptation relies on transforming images from one domain to another. There are two possibilities for the domain adaptation. If the target domain is labeled, then images should correspond to each other. Otherwise images don't have to be matched on a pixel-level. We use two different methods, pix2pix and CycleGAN. Pix2pix is an example for conditional GANs where the training is done by providing pairs of images. (See Fig below)
|
|
|---|---|
| Real image scene | Simulated image scene |


|  |
|---|---|
| simulated scene | transformed into target domain with pix2pix |
|
|
| simulated scene | transformed into target domain with CycleGAN |



Domain Randomization
The idea behind domain randomization is to add random effects to images, to emulate real world variability. We can use a simple renderer such as PyBullet and then use a library, for example ImgAug to augment the images. Augmentations may include:
- adding different kinds of noise (gaussian, poisson)
- blur
- adding/removing random pixels
- changing hue and saturation
- adding random backgrounds
Some example of augmented images are below.



Object Detection Methods
Mask R-CNN
Mask R-CNN is an instance segmentation method. Instance segmentation is a mix of semantic segmentation, where each pixel in the image is classified, and object detection, where the goal is to detect objects using bounding boxes, meaning every pixel is not only classified but different instances of one class are labeled differently. MaskRCNN is an extension of FastRCNN by adding another branch that outputs the object's mask. We use the following implementation. We train the network with the different data generation methods. There are two examples of the outputs of a trained network when fed with a real image of the scene.


Experiments
| Exp. # | methods | #images | precision | recall | comment |
|---|---|---|---|---|---|
| 1 | CycleGAN (DA) | 400 | 104 / 134 | 104 / 124 | |
| 2 | pix2pix (DA) | 400 | 99 / 114 | 99 / 124 | |
| 3 | photo-realistic rendering | 105 | 113 / 115 | 113 / 124 | using real images to train the network |
| 4 | photo-realistic rendering | 300 | 101 / 108 | 101 / 124 | scanned models with real cell backgrounds |
| 5 | DR | 400 | 105 / 124 | 105 / 124 | |
| 6 | DR | 300 | 109 / 146 | 109 / 124 | using textured models |
| 7 | photo-realistic rendering + simulated data | 105 + 200 | 117 / 117 | 117 / 124 | no augmentation for training, real images are used as a substitute for photo-realistic rendering |
| 8 | photo-realistic rendering + DR | 105 + 200 | 118 / 118 | 118 / 124 | real images are used as a substitute for photo-realistic rendering |
| 9 | photo-realistic rendering + CycleGAN (DA) | 105 + 200 | 112 / 112 | 112 / 124 | real images are used as a substitute for photo-realistic rendering |
| 10 | domain randomization + CycleGAN (DA) | 105 + 200 | 106 / 128 | 106 / 124 |
Most important takeaways include:
- for Domain Adaptation experiments
the precision is better than recall for each experiment
- for Domain Randomization experiments
Photo-Realistic Rendering Experiments
- for combined experiments