Introduction
The latest innovations in Deep Learning have introduced many advances as well as new tasks combining multiple areas of research. From a huge evolution in pure Computer Vision tasks such as image recognition or object tracking in video sequences to the latest LLMs released by OpenAI, Google, or Meta (GPT4 and ChatGPT, Bard, LLaMa,…) able to have real-time conversations with humans. Vision and Vision Language Tasks combine the advances in both areas for solving new tasks that can be benefited from explanations in natural language to understand the decisions and inference process of this DL models.
Visual Question Answering [1]
This Vision-Language task was first introduced in 2015. It consists of given an image and a free-form, open-ended question in Natural Language; providing an answer in Natural Language. It is the mainly studied Vision-Language task for the generation of Natural Language Explanations. The differential factors with other V-L tasks are:
- VQA requires a deep understanding of the image and often certain underlying context or real-world knowledge to provide an accurate answer.
- VQA can be automatically evaluated since many open-end questions contain a closed set of answers. Important to evaluate the progress on the task.
- VQA differs in image captioning or similar tasks because requires not only a general understanding of the image and its components but a detailed focus on the aspects related to the question. i.e: you can generate a caption of a picture “A person having a picnic”, but answering the question “Which color is the picnic tablecloth in the picture?” requires an understanding of what’s a picnic, a tablecloth/towel or similar and capability to differentiate at least the basic colors.
The authors of the paper that first introduced the task provided a dataset including over 250K images, 760K questions, and around 10M answers combining images from MSCOCO and abstract images.
They conducted surveys to evaluate the quality and difficulty of the dataset as well as the knowledge required to answer its questions. The results show that even with a majority of 1-3 word answers (95%), the task is difficult enough for a model, such that their proposed model performed similarly to a 4-5-year-old kid. At the same time, the simplicity of the answers to such open-end questions allows an automatic evaluation of the model performance. This shows interest in the task for many different areas, especially using task-specific datasets, for example for medical domain question answering.

Figures 1 and 2: VQA samples: one from the MSCOCO dataset and one from the abstract set of images, respectively.
Importance of the topic and use cases:
How can the medical (and other) domains be benefited from the generation of NLEs of Vision or Vision-Language tasks?
We can distinguish 2 types of explanations for Visual tasks:
- Extractive rationale → Selecting the input features responsible for the prediction
- Natural Language Explanations → Easier to understand by humans, more descriptive and detailed justifications.
NLEs offer higher explainability, this makes the black-box decision process of the models easier to trust by the users in comparison to pointing the input features and areas of the image responsible for the prediction
In addition, NLEs can also be introduced in the development process to detect the origin of biases in the models; or in the learning process, to improve the data efficiency in the learning loop [4]. As pointed out by [4], this can make a huge difference when the datasets are small as is usually the case in medical applications (we’ve seen this in other presentations with datasets of a few dozen or a pair of hundred labeled images)
Datasets
VQA-X and ACT-X [4]
Introduced in 2018, they extend previous datasets with the focus of generating multi-modal explanations for the tasks of Visual Question Answering and Action Prediction:
- VQA-X extends VQA and VQA-2, the latest introduced complementary pairs of questions. These are pairs of semantically similar images with the same question and different answers, which have been demonstrated to improve the performance in both VQA and explanation generation. For the textual explanations, they collected 1 explanation for each training sample and 3 for the test/validation samples from human annotators.
- ACT-X: Action Explanation Dataset. Generated from the MPII Human Pose, containing images extracted from Youtube videos of almost 400 different activities. In this case, they collected explanations asking the annotators to fill in “I can tell the person is doing (act) because…” with at least 10 words. Even though it was introduced in the same research, this paper had less relevance in the later research for the V-L NLE task.
In the paper, the authors also collected justifications for the visual explanations from humans to evaluate their MultiModal Explanation model PJ-X (Pointing and Justification).
e-SNLI-VE [7]
Based on the task of inference proposed by the Stanford Natural Language Inference dataset of given a Premise and a Hypothesis predict if the hypothesis is a Contradiction, Neutral, or Entailment. e-SNLI [6] extends SNLI by adding explanations and SNLI-VE proposes a dataset for Visual Entailment. The authors of e-SNLI-VE introduced a corrected version, SNLI-VE 2.0, and added NLE to the dataset.
SNLI-VE used the images of Flickr30k as Hypothesis, from where the Hypothesis in the original SNLI dataset where generated. Introducing back the original images added a certain context that alters the correct label. SNLI-VE 2.0 corrects these errors only for the test and validation set for the most affected class, the neutral label.
To build e-SNLI-VE the authors of this work used the explanations from e-SNLI that correspond to the correct labels in SNLI-VE2 and for those neutral Image-Labels pairs where the label was corrected, they collected new explanations from human annotators ensuring again the quality of the data collected with systematic checks. The authors also noticed that their explanations were more image specific than the originals from the e-SNLI set and stated that would be beneficial for future works to collect new explanations for the complete SNLI-VE2.0 for the new models trained on to learn more convincing explanations about the images.

Figure 3: Example of SNLI-VE sample that needed to be corrected in SNLI-VE 2.0
CLEVR-X [5]
Its authors pointed out the issues of the aforementioned datasets due to the origin or nature of their explanations. The explanations are collected by humans, which is time-consuming and expensive. In addition, their quality is highly variant; they can be very simple by just describing the image or justifying the answer as “this because this” (which is quite common in e-SNLI-VE).
To address this issue they propose CLEVR-X, extending the synthetic CLEVR dataset with multiple structured NLEs: 3.6M explanations for the 850k Q-Images pairs. They claim the correctness and completion of their explanations since they are synthetically constructed without decreasing the human understandability of the explanations.
The images in CLEVR consist of a set of 3 to 10 objects with different properties: 2 sizes, 8 colors, 2 materials, and 3 shapes. A total of 96 combinations of properties. There are 9 different question types:
- Hop questions: With zero to 3 hop questions, containing from 0 to 3 relations in objects.
- Compare and Relate Questions: Imply comparing the properties of the objects in the image
- Single and/or questions: Questions containing logical AND / ORs.
Dataset Generation
- Tracing the functional program: The answers to the questions can be traced as a functional program on the scene graph. The results of the execution are stored to collect all the information needed to generate the explanation and skip the information that is not necessary to answer the questions.
- Relevance Filtering: To keep a reasonable explanation length, the properties of the objects that are not necessary to answer the question are filtered out
- Explanation Generation: To obtain the NLE, each question type has different templates that are filled with the variables extracted from the functional program trace. To add variability and a larger vocabulary, some properties are randomly replaced by synonyms, except those properties mentioned in the question. When there are multiple objects their order is randomized and repetitive descriptions are aggregated to shorten unnecessary long explanations.
As the original CLEVR test set is not available (scene graphs and functional programs), the authors of CLEVR-X use the validation set of CLEVR as a test set, and 20% of it as a validation set for CLEVR-X

Figure 4: Example of a CLEVR-X sample generation using the described framework
Dataset analysis and comparison with VQA-X and e-SNLI-VE
CLEVR-X contains 2-3 times more images than VQA-X and e-SNLI-VE, more than 20x questions than VQA-X and 2x e-SNLI-VE, and significantly more explanations than both. Their questions and explanations are around 2x larger with an average of 21.53 words per explanation, being 7 words the shortest and 53 the longest. They filter unnecessary information to explain certain answers, causing a very strong correlation between large questions and large explanations. However, due to their synthetic nature, the vocabulary of the explanations is very reduced, with only 96 different words.
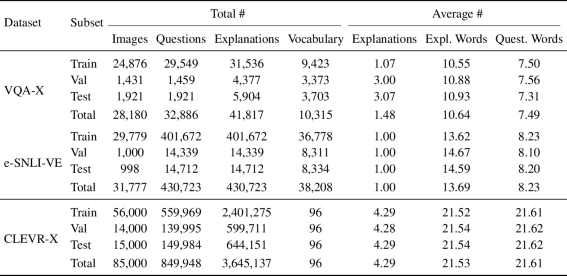
Table 1: Datasets size comparison: CLEVR-X, VQA-X, and e-SNLI-VE
Methods
e-ViL [7]
The authors of e-SNLI-VE proposed e-ViL as a benchmark on which to evaluate different architectures using human judges. They proposed a new model e-UG formed by a Task and Explanation model as PJ-X [4] or other previous works. Their model leverages contextualized embeddings of the image-question pairs and achieved SOA performance by a large margin on all datasets.

Figure 4: High-level architecture of different models compared in [8]
e-UG uses UNITER, a transformer-based Vision Language encoder, and GPT-2 for the explanation generation. In their work, they trained separately the models in each dataset. They pre-trained the task models in the VQA2 and VQA-X datasets and trained from scratch in e-SNLI-VE and VCR. For UNITER they pre-trained following its authors models. e-UG not only achieved the best performance but the generated explanations were the most faithful with a similar % of unjustified answers as other models

Table 2: Models performance comparison when trained only on the V-L task or in the task + explanations generation

Table 3: Main shortcomings of the explanations generated by the evaluated models evaluated by human judges following the e-ViL framework.
NLX-GPT [9]
The models proposed in [1,4,5,6,7,8] all share a common structure: They are composed of a task model M_T dedicated exclusively to solving the task and an explanation generation model M_E stacked on top for generating an explanation in Natural Language form for the output of the task model.

Figure 4: Comparison of models with M_T and M_E stacked (left) and models with only M_E
The authors of this work use only an explanation model to address this task formulating the answer task as a text generation task with the corresponding explanation. This approach reduces the memory required and speeds-up inference time up to 15 times, performing better than previous SoA models.
In addition produces more associated answer-explanations pairs, since they are produced by the same model, solving the de-coupling problem of certain previous models and making the explanations more consistent with the answer, no matter if the answer was correctly or wrongly predicted. When the task and explanation are generated by different models the explanations cannot reflect the actual inference process since each model can learn different features, biases, or shortcuts from the datasets.
The model:
NLX-GPT is composed of a CLIP visual encoder that produces non-biased general embeddings similar to the language embedding space of the decoder; a distilled GPT-2. All the text is given a unique input sequence to the model and trained with Cross Entropy loss to generate a sequence of T words:
| L = -\sum{log\space{p_\theta}(w_t|w_{<t})} |
This structure also allows using other models to generate the answer and generate the explanation with NLX-GPT. For this, the answer needs to be appended after the question and given as input to NLX-GPT
As explained previously, our task requires a deep understanding of the images to avoid that the model learns biases and shortcuts in the dataset. For this, the model was pre-trained on a large caption generation dataset, as is aligned with the text generation and image understanding task. They noticed that pre-training was not enough for generalization on the e-SNLI-VE dataset. To fix it they added a Multi-layer Perceptron on top of the visual encoder to improve the image concept understanding. Then the model was fine-tuned for the NLE with a batch size of 32 using VQA, e-SNLI-VE, and VCR.
Evaluation
The model is evaluated with the usual NLG metrics (BLEU, METEOR, ROUGE-L, CIDER, SPICE, and BERT-Score) and by humans following the work of [7] for their model e-UG.
They pointed out the problems of these metrics as they don’t reflect the quality, truthfulness, or correctness of the explanations, since models can learn shortcuts or biases in the datasets. As an alternative to the expensive human evaluation they propose 2 new automatic evaluation metrics:
- Explain-predict: To measure the quality of explanations, by measuring the answer and explanation are correlated, the question and explanation are inputted in a language representation model that aims to predict the answer.
- Retrieval-based Attack: Similar images are queried using an image-retrieval model and fed to the model with the same question. The generated explanations are fed into a language model to obtain a vectorial representation. The distance of each vector with the average vector represents the bias. The lower this distance is, the lower the bias.

Figure 5: Explain-predict framework (left) and Retrieval-based attack (right)
For their experiments, they used VQA-X, ACT-X, e-SNLI-VE, and VCR reformulating it as a text generation task, but it was left out of the main results due to task differences. They present the results in 2 variants:
- Filtered: They considered that incorrect answers will lead to incorrect explanations, so when the answer predicted is wrong it is not considered for the evaluation.
- Unfiltered: All explanations are evaluated, independently of the predicted answer
The model outperformed all previous works in the unfiltered variant in VQA-X and ACT-X and also did in almost all the NLG metrics for the filtered variants in the VQA-X and e-SNLI-VE datasets. However, the metrics where it performed worse for e-SNLI-VE are highly correlated with human metrics. Their results show how model pre-training helps in the NLE generation. They point to a better performance with the CLIP vision transformer encoder, but also compared their work with previous using a ResNet-101, as the others did, still reporting better performances.

Table 2: Evaluation metric scores of NLX-GPT in VQA-X and e-SNLI-VE. Filtered variant
S3C [10]
The authors pointed out the main challenges of the 2 paradigms for NLE generation previously mentioned. In addition to the problems of the extractive rationale paradigm, already pointed out by [9], they pointed out how self-rationalization models suffer from logical inconsistencies when generating the NLEs and both paradigms require labeled datasets, expensive to generate. To address this issue they propose a Semi-Supervised VQA-NLE method with Self-Critical Learning S^3C that outperforms previous SOA models on the presented datasets.
Their method uses prompt learning to improve the performance of the models on the downstream task in comparison to fine-tuning because when comparing it to fine-tuning, self-prompting can maintain the optimization of the pre-training task as previous literature suggests (See original paper for the original sources) together with RL.
For pre-training they also used a CLIP visual encoder to fine-tune a language model for image captioning.
The S^3C framework is formed by 2 modules:
- The Answer-Explanation Prompt Module: They use 2 templates, one to generate answers and the other for explanations; they are trained for generating text for both tasks, this way the model can produce answers and explanations without a predefined answer space. The model receives as input the image, question, and ground-truth answer and the corresponding templates. In case there is a ground-truth explanation it is also passed into the model as can be seen in Figure 6. They computed the loss only for the labeled Q-A pairs with explanations.
- The Self-Critical Module: To gain logically consistent rationales they expand the searching space by introducing a sequence sampling algorithm and generating a set of candidate explanations, treating the answers as self-critical rewards for the RL agent to achieve an end-to-end training. The explanation generation process generates multiple explanations using beam search and their templates, which benefits the training by expanding the search space and preventing it from overfitting. The gradient for the RL algorithm is calculated by:
 RL calculation where: p_\theta^r(A) denotes the answer average probability, p_\theta^b(A) the output average probability, A the ground-truth answer for the sample, and p_\theta(r_k) the probability of the k-th explanation.
RL calculation where: p_\theta^r(A) denotes the answer average probability, p_\theta^b(A) the output average probability, A the ground-truth answer for the sample, and p_\theta(r_k) the probability of the k-th explanation.

Figure 6: Overview of S^3C with example inputs for a labeled and unlabelled sample.
The R explanations generated are then appended to the QA pair in a new template and fed back to the model in an RL method, assuming that the answer scores can be used as the RL rewards to evaluate the explanations and achieve end-to-end training.


Tables 3 and 4: Evaluation results on the VQA-X dataset for the unfiltered and filtered variants, respectively
Results:
To evaluate their work they used VQA-X and A-OKVQA (another VQA dataset that requires more common knowledge to answer correctly) as supervised datasets and VQAv2.0 and OK-VQA as unlabeled NLE datasets. e-SNLI-VE or similar were not used as they slightly differ from the VQA task.
They used the same metrics and methods as in [9] for the automatic evaluation.
For the human evaluation, they asked 3 humans to evaluate each test sample and computed an average. In addition, they were asked to say if the explanation was sufficient, incomplete, or non-sense.
The evaluation results show how this method outperforms all previous works in all metrics for the unfiltered and filtered method and how the Semi-Supervised method boosts the performance even more. Remarkably, their setup used a VL encoder less powerful and less pre-trained than in NLX-GPT.
Finally, they also performed cross-dataset evaluations. The results demonstrated the capabilities of S3C to learn and generalize from one dataset to another performing better than NLX-GPT in all metrics.
The human evaluation results showed that S3C can obtain relatively better explanations
ALICE [3]
Active Learning with Contrastive Explanations. Expert in the loop framework to address the challenges of generating labeled datasets for natural language explanations, especially in areas where a high knowledge domain is required.
To improve data efficiency in learning ALICE uses:
- Active Learning: allowing it to select the data to learn from instead of learning from random samples increases its performance because selects the most informative pairs of label classes to elicit explanations from domain experts
- Contrastive NLEs: Asking experts about the difference between the most similar pairs can help learners better understand the features to distinguish them. This is supported by social studies that show how humans learn faster with contrastive learning and such kind of explanations, i.e. explanations to questions of the type “Why this is X and not Y?”
Their work differentiates from others that already showed good results when incorporating NLEs into classification tasks [11,12] in the focus on a limited budget or time to interact with domain experts, focusing on eliciting less but more informative and relevant NLEs. To achieve this they incorporated contrastive explanations to the model hierarchy limiting the number of rounds of interaction with domain experts and the budget for the queries.
The model is formulated as:
| M( φ , g_{pool}, f) = f(g_{pool}( φ (x))) |
Where φ is an image encoder that maps each input image x to an activation map. g pool is a global pooling layer and f is a fully connected layer to classify the sample into C classes.
ALICE performs multiple rounds of interaction with domain experts and dynamically updates the learning model’s structure during each round:
- Class-based Active Learning. Projects each class’s training data into a shared feature space g_{pool}( φ (x)) . Then ALICE selects b most confusing class pairs to query domain experts for explanations - the closest b pairs in the projected space. The optimization objective is to reduce the required expert queries
- Semantic Explanations Grounding. ALICE then queries NLEs for these b pairs. Each query only contains textual information and the pairs of classes the model considers for each sample. The explanations received are parsed using a simple semantic parser and the extracted knowledge is propagated to all samples of those classes on the training data cropping the corresponding semantic segments to incorporate it in the learning model for later training.
- Neural-Archutecture Morphing: Finally allocates a new local classifier per explanation and merges the b class pairs in the global classifier. The model starts with a C-class classifier that after each round gets updated to C = C -2b + b . Each b new local classifier performs a binary classification for one class pair when the global classifier predicts that the sample belongs to one of those original classes. The cropped image patches are used as additional training data for a newly added local classifier to emphasize these patches' importance.

Figure: ALICE 3-step workflow. 1. Class-based Active Learning. 2. Semantic Explanations Grounding. 3. Neural-Archutecture Morphing.
For training they fine-tuned the image encoder, Inception v3, re-training the classifier after each round. The global classifier is trained with the original images adapting the classes after each iteration, but the local classifiers introduced after each query are trained using the resized image patches obtained in the semantic explanation grounding step. The model supports many classifiers, not only binary. The framework is also agnostic to the design of the local classifiers, any design could be used in ALICE using shared attention by the local classifiers to share the knowledge for detecting the most relevant.
Their results show how adding contrastive NLEs can in the learning loop can improve the performance by being more data efficient. The empirical results show an improvement similar to introducing 30 and 13 new labeled data points per each NLE introduced in the bird species and social relationship classification datasets used for the experiments. Their results also proved that the hierarchical neural architecture introduced improves the classification performance.

Table: Test accuracy comparison among variants of ALICE on the social relationship classification task

Figure: Performance gain comparison of adding contrastive NLEs and new data points on social relationship classification.
Conclusions and personal takes
In this post, we reviewed and pointed out the difficulties of generating datasets for the task of Natural Language Explanations for Vision Language tasks. These difficulties are even more noticeable in the medical domain.
To address these difficulties some of the work reviewed propose different techniques to increase data efficiency during the learning phase. I personally would highlight ALICE since it allows to incorporate in an effective and efficient manner the knowledge of experts in the domain considering the possible dataset size or budget limitations, reaching a significant boost in performance. This technique has proven to be a very efficient NLP data augmentation technique [11].
The review of the latest works such as [9, 10] suggests that the research path for the NLE models will go towards the use of a single LLM (with a visual encoder to encode the images) for both solving the task and generating the natural language explanations, for example, BART or one of the latest GPT versions.
Finally, it is worth mentioning that there are some works in the presented task of VQA under the medical domain, unfortunately, the majority focus only on solving the question-answering task and the visual entailment. but don't generate NLEs. One of the latest works is SurgicalGPT [12] which uses again GPT-2 and a Visual Encoder for answering questions related to surgical images. This model also showed better performance when compared to previous works, which again suggests that LLMs trained in text generation can be the way to go in this research area. The preseasons for this are, as OpenAI suggests in their GPT3 paper, that LLMs are good Few-shot learners [13] and that training LLMs for text generation and later on fine-tuning them for the down-stream task using prompting can show very good results with only a few data-points [14] even in very specific domains as the medical domain.
References
[5] Salewski, L., Koepke, A. S., Lensch, H. P. A., & Akata, Z. (2022). CLEVR-X.
[9] Sammani, F., Mukherjee, T., & Deligiannis, N. (2022). NLX-GPT. arXiv preprint arXiv:2203.05081.
[11] Prof. Dr. Georg Groh Tobias Eder, M.A. M.Sc. - Advanced NLP - CIT4230002. 4.Data for NLP.
[13] Brown et al. 2020. Language Models are Few-Shot Learners
[14] Prof. Dr. Georg Groh Edoardo Mosca, M.Sc. - Advanced NLP - CIT4230002. 2. Fine-Tuning.