Facial Landmark Detection is a computer vision topic and it deals with the problem of detecting distinctive features in human faces automatically.
- Tip of the nose
- Corners of the eyes
- Corners of the eyebrows
- Corners of the mouth
- Eye pupils
The detected landmarks are used in several different applications.
Introduction
The following quote introduces to facial landmarks detection: "As computer vision engineers and researchers we have been trying to understand the human face since the very early days. The most obvious application of facial analysis is Face Recognition. But to be able to identify a person in an image we first need to find where in the image a face is located. Therefore, face detection — locating a face in an image and returning a bounding rectangle / square that contains the face — was a hot research area. In 2001, Paul Viola and Michael Jones pretty much nailed the problem with their seminal paper titled “Rapid Object Detection using a Boosted Cascade of Simple Features.” In the early days of OpenCV and to some extent even now, the killer application of OpenCV was a good implementation of the Viola and Jones face detector." (1)
Facial landmark detection is also referred to as “facial feature detection”, “facial keypoint detection” and “face alignment” in the literature. Today more and more approaches with neural networks are developed and outperform classical approaches.
Metric
There are three different metric which are commonly used to measure the performance of facial landmark detection.
- Mean Distance: The mean distance of detected landmarks compared to the ground truth landmarks.
- Mean Error Rate: The mean distance of detected landmarks compared to the ground truth landmarks and divided by the ocular distance of the image.
- Mean Failure Rate: A failure rate for detection is also an important metric. This rate is calculated as the percentage of the detected landmarks within a certain threshold of error or mean distance.
Network Structures
One typical State-of-the-Art structure for a facial landmark detection neural network is shown below.

Figure 1: Network architecture of a facial landmark detection neuronal network. First convolution are applied to the input image, then fully connected layers are applied. (2)
The first part contains convolutions and max pooling operations. This can be interpreted as searching key features inside the input image. Subsequently, a fully connected layer is applied. Neurons which represent the location of each landmark are activated respectively. In the present day, these networks can achieve a mean error rate of 8% (2) .
Applications of Facial Keypoint Detection
There are several applications of keypoint detection in human faces. A few of them are listed below.(1)
Facial feature detection improves face recognition
Facial landmarks can be used to align facial images to an intermediary face shape so that the location of the facial landmarks in all images are approximately the same after the alignment.
Male/Female Distinction
Automatical Landmark Detection can be utilized to distinguish between male and female faces. The distribution of all landmarks is typical for male and female face. Using neural nets and large datasets this pattern can be learned and applied.
Facial Expression Distinction
It is easily possible to get information about the facial expression of someone with use of landmarks.
Head pose estimation
Once a few landmark points are known, it is possible to estimate the pose of the head as well. In other words, it is possible to figure out how the head is oriented in space, to which direction the person is looking at. This information can be used for several applications for example driver assistance systems.
Face Morphing
Facial landmarks can be used to align faces that can then be morphed to produce in-between images. Figure 2 shows are visualization.
Virtual Makeover
The detected landmarks can be used to the calculate contours of the mouth, eyes etc. to render makeup virtually. Figure 3 visualizes the application of virtual makeovering.
Face Replacement
If facial feature points estimations on two faces are present, it is possible to align one face on the other one, and seamlessly clone one face onto the other one. On figure 4 you can see the result of a face replacement application.


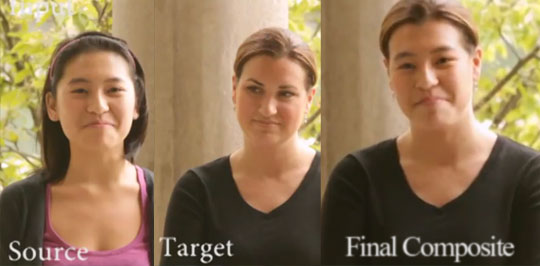
Literature
- http://www.learnopencv.com/facial-landmark-detection/ (Last visited: 23.01.2017)
- http://mmlab.ie.cuhk.edu.hk/projects/TCDCN.html (Facial Landmark Detection by Deep Multi-task Learning; Zhanpeng Zhang, Ping Luo, Chen Change Loy, Xiaoou Tang)
- https://computingforpsychologists.files.wordpress.com/2011/09/bush-arnie-morph.jpg
- http://www.learnopencv.com/wp-content/uploads/2015/10/taaz-before-after.jpg
- http://hight3ch.com/wp-content/uploads/2011/12/video-face-replacement.jpg
Weblinks
- https://arxiv.org/pdf/1511.04031v2.pdf (Facial Landmark Detection with Tweaked Convolutional Neural Networks; Yue Wu, Tal Hassner, KangGeon Kim, Gerard Medioni, Prem Natarajan)
- https://www.ics.uci.edu/~xzhu/paper/face-cvpr12.pdf (Face Detection, Pose Estimation, and Landmark Localization in the Wild; Xiangxin Zhu, Deva Ramanan)
- http://mmlab.ie.cuhk.edu.hk/projects/TCDCN.html (Facial Landmark Detection by Deep Multi-task Learning; Zhanpeng Zhang, Ping Luo, Chen Change Loy, Xiaoou Tang)
- http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Wu_Robust_Facial_Landmark_ICCV_2015_paper.pdf (Robust Facial Landmark Detection under Significant Head Poses and Occlusion; Yue Wu Qiang Ji)
- http://www.learnopencv.com/face-swap-using-opencv-c-python/ (Face Swapping Example)
- http://www.taaz.com/ (Virtual Makeover - Application Examples)
- http://jivp.eurasipjournals.springeropen.com/articles/10.1186/s13640-016-0103-z (Head Pose Estimation - Application Example)
- https://www.kaggle.com/competitions (One of the most famous facial landmark detection competition; Kaggle)
2 Kommentare
Unbekannter Benutzer (ga69taq) sagt:
30. Januar 2017General problems and suggestions:
Corrections (note that some of the corrections have more than one changes):
Final comments:
Unbekannter Benutzer (ga63muv) sagt:
31. Januar 2017Hi, Martin,
All the following arguments are highly subjective!
Aykin's comments covered almost all the shortcomings of you wiki, so I just added something from my view.
Suggestions:
Corrections:
The detected landmarks can be used to the calculate contours of the mouth, eyes etc. to render makeup virtually.
The detected landmarks can be used to the calculate contours of, for instance, mouth, eyes and so on, to render makeup virtually.
Final Comments: