Introduction
This blogpost reviews the paper "Chest Radiograph Disentanglement for COVID-19 Outcome Prediction"[1] written by Lei Zhou, Joseph Bae, Huidong Liu and others.
Motivation
Chest radiographs are one of the most frequently performed medical imaging techniques in clinical practice and used for diagnosing a variety of conditions. Time pressure from this increasing workload combined with night shifts, limited experience or other factors lead to misdiagnosis – even for the best radiologists. However, by leveraging these large image datasets, recent deep neural networks have shown chest x-ray classification performance similar to radiologists [2]. These computer-aided diagnosis systems help improve the diagnostic quality of the average radiologist.
Related Work
This paper refers to several works, one of them is Swapping AutoEncoder (SAE) [3]. It is a deep model designed especially for image manipulation, rather than random sampling. The key idea is to encode an image with two independent components and enforce that in the resulting image any swapped combination maps to a realistic image. Images are encoded as a combination of two latent codes representing structure and texture respectively. The SAE is also forced to synthesize the target texture supervised by patches sampled from the target image.
Paper Contributions
Researchers of the paper proposed LSAE or Lung Swapping AutoEncoder:
- to extract texture from structure in CXR images, enabling analysis of disease-associated textural changes in COVID-19 and other pulmonary diseases.
- also LSAE was used to create a data augmentation technique which synthesizes images with structural and textural information from two different CXRs images.
Methodology
Lung Swapping AutoEncoder (LSAE)
Lung Swapping Autoencoder (LSAE), that learns a factorized representation of lung images to disentangle/extract the tissue texture from the anatomic structure representation. New Autoencoder was introduced because vinalla SAE does not fit problem due to following reasons:
- First, during sampling texture patches from target image, irrelevant out-of-lung textures reduce the effect of the in-lung texture transfer. (as the infiltrates of interest are located within lung zones)
- More importantly, irrelevant structure signs may influence the hybrid image, because texture supervision is obtained from image patches, as a result in unacceptable lung form deformation and interference with successful disentanglement.
These problems were addressed as follows: - First, the disease level in Image hybrid is usually diminished when compared with one of source images. Authors hypothesize that the out-of-lung irrelevant texture patterns may hinder target texture synthesis in Image hybrid . During sampling areas from the lung were used instead of the whole image for texture supervision. To ensure the texture in hybrid image matches source image, researchers adversarially train a patch discriminator {D_{patch}}to supervise the texture synthesis within lungs.
- Second, since there is no structure supervision in SAE, Image hybrid shows undesired lung shape distortion towards image source . This leads authors to propose a design with two new features, in-lung texture supervision and out-of-lung structural distortion suppression. To ensure hybrid image maintains the structure of Image 1 , researchers apply a patch contrastive loss outside the lungs to minimize structural distortion.
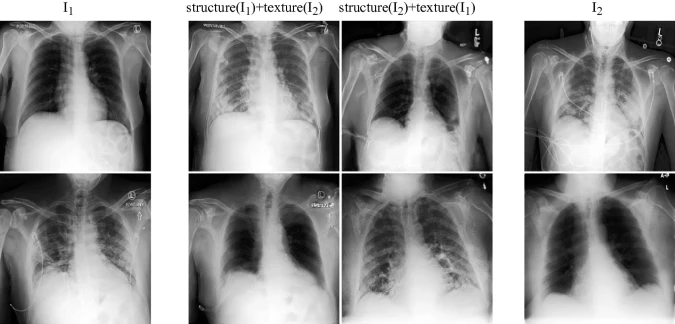
Lung Swapping Result. Two examples of lung swapping between images in column I1 and images in column I2. The Lung Swapping Autoencoder (LSAE) is able to successfully transfer target lung textures without affecting the lung shape. The swapping results are shown in the second and the third columns.
Dataset
- ChestX-ray14
- medical imaging dataset which comprises 112,120 frontal-view X-ray images of 30,805 (collected from the year of 1992 to 2015) unique patients with the text-mined fourteen common disease labels [9]
- training (∼70%), validation (∼10%), and testing (∼20%)
- LSAE, trained on a large public CXR dataset, ChestX- ray14, can generate realistic and plausible hybrid CXRs with one patient’s lung structure and another patient’s disease texture - COVOC
- multi-institutional COVID-19 outcome prediction dataset, 340 CXRs from 327 COVID-19 patients
- labeled based upon whether the patient required mechanical ventilation
Experimental Design and Results
Swapping AutoEncoder (SAE)
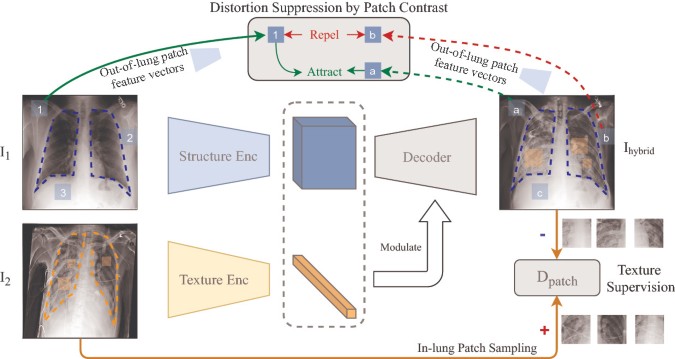
Image 2[1]
Two sampled images I_1 and I_2 are first encoded as (z_{1s}, z_{1t}) and (z_{2s}, z_{2t}). Then, in order to get a hybrid code (z_{1s}, z_{2t}), the latent codes are swapped. Finally, the hybrid code is decoded to yield a hybrid image I_{hybrid} which is expected to maintain the structure of I_1 but present the texture of I_2. In the paper was used G to denote the composite generation process as
| G(I_1,I_2) = Dec( Enc_S(I_1), Enc_t(I_2)) |
Texture Supervision
To guarantee that generated image texture matches source image texture, SAE samples patches from source image to supervise the hybrid image texture. Patch discriminator D_{patch} is trained to distinguish patches in I_{hybrid} from patches in I_2. SAE is trained adversarially to generate a I_{hybrid} whose results can confuse D_{patch} by mimicking the texture of I_2. The texture loss is formulated as
| L_{tex} = E (-log(D_{patch}(a_1(I_2),a_2(G(I_1, I_2))) )) |
In-lung Texture Supervision
Due to the reason that out-of-lung texture could influence to result of generated image, only patches from in lung zone are sampled. A lung segmentation mask was used and a_1,a_2 samples were replaced from Lung mask ones, only patches from in lung zones were used in generator G training.
Out-of-Lung Structural Distortion Suppression
Patch contrastive loss, based on Noise Contrastive Estimation, was introduced in LSAE in order to handle structural distortion. It helps to preserve image content in image generation tasks. It is presented as cross-entropy loss, where p is a bag of feature vectors of hybrid image encoded with structural Enc_s.

Hybrid Image Augmentation
If the texture in I_2 can be transferred to I_{hybrid}, it was assume that the label or ventilation property of I_2 is also attached to I_{hybrid}. Based on this hypothesis, a new data augmentation method could be designed:
- Given an image I_{dst} in the target domain, for example COVOC dataset. Then K sample images I_{src} from a source domain, e.g., ChestX-ray14.
- LSAE is used to get I_{dst} as the texture template and images from I_{src} as structure templates to generate K hybrid images I_{hybrid}.
- I_{hybrid} images are marked with the label of I_{dst}.
Following this protocol, training set enlarged in target domain K times.
Conclusion
Implementation
Decoder and discriminator architectures follow StyleGAN2. Encoders are built with residual blocks. Code is available on Github. The texture encoder outputs a flattened vector while the structure encoder’s output preserves spatial dimension. LSAE is optimized by Adam with learning rate 1e-3, code is based on PyTorch 1.7.
Results
A new metric was proposed, Masked SIFID, to measure the disease level distance between Image hybrid and Image 2 . Masked SIFID is based on the SIFID which calculates the Fréchet inception distance (FID) distance between two images in the Inception v3 feature space.

Image 3 [1]
- In Image 3 (left), LSAE achieves lower Masked SIFID when compared with SAE, approximately for 10%
- Left. On the hybrid image generation task, LSAE performs better than SAE in both texture synthesis and structure maintenance.
- For the 14 pulmonary diseases classification task on the large-scale ChestX-ray14 database (N = 112,120), they achieved a competitive result (mAUC: 79.0%) with unsupervised pre-training.
 Image 4 [1]
Image 4 [1]
- As COVOC dataset is imbalanced, the ventilation prediction was reported with Balanced Error Rate (BER) and mAUC in Image4. Compared with Inception v3, Enc_treduces BER by 13.5 %, and improves mAUC by 4.1 %.
- Moreover, when compared with Inception v3 on multi-institutional COVID-19 dataset, COVOC (N = 340), for a COVID-19 outcome prediction task (estimating need for ventilation), the texture encoder achieves 13% less error with a 77% smaller model size, further demonstrating the efficacy of texture representation for lung diseases.
Personal Review
The authors of the paper solve prediction and data augementation problem of CXR images in interesting way.
First, using LSAE for data augmentation by generating hybrid lung images. Models based on CT images are better at predicting COVID-19 outcomes in comparison to CXR-based models due to the lack of COVID-19 CXR datasets. Publicly sourced datasets [4] datasets tend to be homogeneous, and often lack disease outcome labels. Also widely used data augmentation techniques such as GANs or Autoencoders are not suitable for CXR generation due to the lack of explicit structure supervision, which can lead to generating distorted shapes [1].
Secondly, approach to disentangle chest CXRs into structure and texture representations reached better performance and was supported by other works, to be precise that COVID-19 on CXR is observed within ling areas and their extent and location is associated with disease severity and progression [5,6].
On the other hand, by authors of the paper usage of GAN loss was not introduced in fully manner. Moreover, there is lack of comparison to other competitive methods and compared works are questionable. For example, ChestNet[7] is Multivariable logistic regression model, which design and approach differs from Transformers. Another example is CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning, the paper was published in 2017 [8] , 3 years gap could play significant role in comparison.
References
- Zhou, Chest Radiograph Disentanglement for COVID-19 Outcome Prediction, 2020
- Rajpurkar et al., Deep Learning for Chest Radiograph Diagnosis: A Retrospective Comparison of the CheXNeXt Algorithm to Practicing Radiologists.PLOS Medicine 15, no. 11, 2018.
- Park, T., Zhu, J.Y., Wang, O., Lu, J., Shechtman, E., Efros, A.A., Zhang, R.: Swapping autoencoder for deep image manipulation. arXiv preprint arXiv:2007.00653 (2020)
- López-Cabrera, J.D., Orozco-Morales, R., Portal-Diaz, J.A., Lovelle-Enríquez, O., Pérez-Díaz, M.: Current limitations to identify COVID-19 using artificial intelligence with chest X-ray imaging. Heal. Technol. 11(2), 411–424 (2021). https://doi.org/10.1007/s12553-021-00520-2 CrossRef
- Toussie, D., et al.: Clinical and chest radiography features determine patient outcomes in young and middle age adults with COVID-19. Radiology 201754 (2020)
- Wong, H.Y.F., et al.: Frequency and distribution of chest radiographic findings in COVID-19 positive patients. Radiology 201160 (2020)
- Wang, H., Xia, Y.: Chestnet: a deep neural network for classification of thoracic diseases on chest radiography. arXiv preprint arXiv:1807.03058 (2018)
- Rajpurkar, P., et al.: Chexnet: radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv preprint arXiv:1711.05225 (2017)
- Wang et al. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases (2017)