This is the blogpost for the paper “Graph Meta Learning via Local Subgraphs”.
Written by Kexin Huang, and Marinka Zitnik.
Introduction
Graph Neural Networks(GNNs) have resulted successfully on different domains such as recommender systems[1], molecular biology[2, 3], or knowledge graphs[4, 5]. However, there is one slight problem with GNNs and graph data in general, which is not having a large dataset and label set. Therefore, in order to tackle this problem. What learned with one dataset is being used in another one, just like in a few-shot learning fashion.
There are different ways how meta-learning might work for GNNs. However, if one wants to explain; there are three possible settings for meta-learning:

Figure 1: Graph meta-learning problems with different settings
To tackle this problem, a novel method is introduced which is called G-META. G-META tries to represent every node with local sub-graphs and trains GNNs with these local sub-graphs to meta-learn. Furthermore, this is supported by a hypothesis which is local sub-graphs around the target node are enough to train GNNs rather than using the entire graph. While using the entire graph is helpful in a few-shot setting, it is not helpful when GNNs try to capture the structure of the local sub-graphs. The local sub-graphs are then used to get structural similarity between target nodes and support nodes using the Weisfeiler-Lehman test[6, 7]. In addition, structural similarity brings inductive bias to GNNs which is a core feature for meta-learning in Machine Learning in general. Finally, local sub-graphs would enable GNNs to effectively feature propagate and label smoothing.
Related Work
If one needs to understand G-META or meta-learning in GNNs in general, one needs to understand what meta-learning is.
Meta-Learning
Meta-learning can also be referred to as "learning to learn"[8]. While ML tasks such as image classification, object prediction, etc. are tasks which are dealt with neural networks and large datasets, the large dataset part is not applicable all the time. In addition, some problems might be tackled with ML, and suitable for ML as well; however, they lack large datasets. For example, detecting the genes that are relevant for autism disease is something that attracts ML researchers. However, since there are not enough applicable data that exist to tackle this problem. To solve this, meta-learning comes in.
 Figure 2: Meta learning data set-up[9]
Figure 2: Meta learning data set-up[9]
What meta-learning does is, it tries to understand how an ML algorithm works for different datasets and tries to generalize this algorithm so that it would work for different problems. Generally, meta-learning techniques can be divided into three categories are Model-Based, Metric Based and Optimization Based.
Model-Based Meta-Learning:
This is also referred to as "Black-Box" learning. Like its name suggest, black-box learning is taking a Neural Network, training it for different tasks(a dataset with train(support) data and test(query) data), and optimizing the parameters of that neural network.
Metric Based Meta-Learning:
This is similar to what is being used in current NLP applications. Basically, feature embeddings are calculated for each data in the support set. Then, the embeddings are also calculated for query data. Finally, the similarity between these is calculated with a similarity function such as cosine similarity.
Optimization-Based Meta-Learning:
This is a fairly interesting technique. Basically, there are two learners. There is one learner that is created by the meta learner using its meta parameters. That one learns a task using the support set of the tasks. After that, query sets of the meta-training set are used to predict using the learner that was created by the meta learner. This whole process is called as "Adaptation Process". Then, these predictions are compared with the ground truth, and a meta loss is calculated. Finally, meta parameters are optimized using this loss via a gradient descent fashion.
 Figure 3: Optimization based meta learning explained
Figure 3: Optimization based meta learning explained
A well-known application of optimization-based meta-learning is Model-Agnostic Meta-Learning(MAML)[10], which is the algorithm that is being used in G-META.
MAML
MAML is basically an optimization-based meta-learning algorithm that is widely used. MAML names meta learner as "learner" and neural network in the adaptation process as "adapter". The steps of MAML are given below:
- Randomly initialize the learner
- Feed the adapter with the learner's meta parameters.
- Sample a batch of tasks
- Train the adapter with a certain epoch with the support set
- Feed query set into the adapter and compute the meta loss
- Compute the meta gradient and update the meta parameters
- Repeat steps 2-6
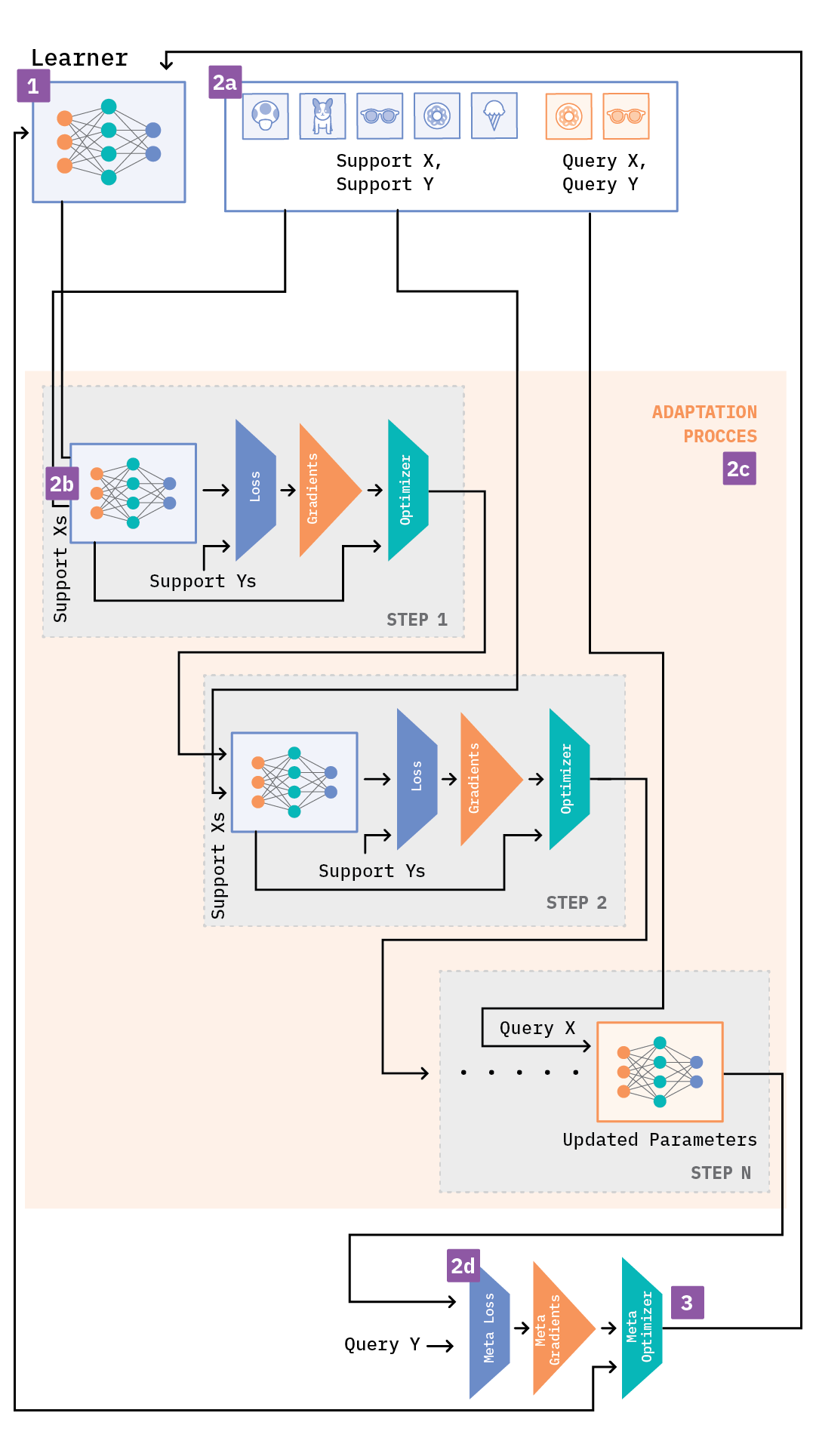
Figure 4: MAML explained
MAML is pretty much similar to the vanilla approach of the optimization-based meta-learning algorithm. The difference is taking the batch approach rather than training the adapter with the entire task set.
Methodology
Previous Work
Few-Shot Meta-Learning:
Few-shot meta-learning is a practical meta-learning method whenever there are a few labels.
Meta-Learning For Graphs:
Researchers work on different techniques for meta-learning for graph-structured data. Liu et al.[11] constructs image category graphs for few-shot learning. Zhou et al.[12] uses graph meta-learning for fast network alignment. MetaR [13] and GMatching [14] use metric methods and there are many more. G-META can handle many settings with graphs and disjoint label sets.
Subgraphs and GNNs:
Extracting subgraphs is essential for GNNs to detect structural similarities. There are different works on extracting and using subgraphs. For example, Patchy-San [15] uses local receptive fields, Ego-CNN uses ego graphs to find critical graph structures [16], Cluster-GCN [17], and GraphSAINT [18] use subgraphs to improve GNN scalability. G-META is the first work on using subgraphs for meta-learning.
 Table 1: Different meta-learning methods and their comparison at different settings
Table 1: Different meta-learning methods and their comparison at different settings
Theoretical Motivation
Let's begin with how to create a local subgraph in G-META. For a node u, a local subgraph is defined as S_u = (\mathcal{V}^u, \mathcal{E}^u, X^u) which holds the condition \{v|d(u, v) \leq h\} at which d(u, v) is the distance between node u and node v; and h is the defined distance for the local subgraph. However, the problem might be with this way of approach is that some information might be lost during the division of the graph into local subgraphs. However, there is a theory stating otherwise; that local subgraphs collectively hold the information of the entire graph. In order to see whether this is true, we have to see two different influence types.
Node Influence: Influence of node u to v.
Graph Influence: Influence of graph G on node u.
Graph Influence Loss: The difference between the influence of graph G and subgraph Su. This determines whether there is an information loss in using the local subgraph method.
In addition, there are two theorems that suggest that the local subgraphs preserve the information about the entire graphs:
 Figure 5: Decaying Property of Node Influence theorem
Figure 5: Decaying Property of Node Influence theorem

Figure 6: Local Subgraph Preservation Property theorem
If one wants to investigate the proofs of these theorems, one can refer to the G-META paper. Thanks to the local subgraph structure, G-META can remember the structure, features, and labels of the graph which enables G-META to do few-shot meta-learning.
G-META

Figure 7: G-META explained
What G-META brings to the table is to create local subgraphs. Then, it creates embeddings for these local subgraphs via a GNN. Finally, it uses prototypical loss for inductive bias and MAML for knowledge transfer.

Figure 8: G-META algorithm
The first step is to create local subgraphs for each node u. A novel subgraph extraction algorithm is being used for that[19, 20]. After that, the subgraphs are given into h-layer GNN at which h stands for the maximum distance in a subgraph between node u and node v. At the end of this step, embeddings for these local subgraphs are created.
Then, in order to leverage inductive bias in a few-shot learning setting; prototypical loss is being used. This loss is something that is defined in the paper. First, label k and its support set graph embeddings' mean is calculated by the given formula:
| c_k = 1/N_k\sum_{y_j=k}h_j |
at which ck stands for the prototype of label k. Then, a class distribution is calculated for each local subgraph via using the euclidean distance:
| p_k = (exp(-||h_u-c_k||))/(\sum_{\hat{k}}exp(-||h_u-c_\hat{k}||)) |
Finally, these distributions are used in an optimization-based meta-learning algorithm(MAML in our case) via extracting the cross-entropy loss of them in the given formula:
| L(p,y) = \sum_{j}y_jlog(p_j) |
In addition, the MAML algorithm, which is one of the most popular optimization-based meta-learning algorithms, is being used. As it is given in Figure 6, stochastic gradient descent is being used for the optimization step.
Finally, G-META is a very attractive approach in order to tackle graph meta-learning problems due to its Scalability, Inductive Learning, Over Smoothing Regularization, Few-Shot Learning, Broad Applicability.
Experiments and Results
Two synthetic datasets are used whose labels depend on the local structure in order to prove G-META's performance over capturing local graph structures.

Table 2: Dataset Statistics. Fold-PPI and Tree-of-Life are new datasets introduced in this study.
Which are Cycle dataset that contains cycles which create some shapes such as a star or a diamond. BA dataset is a Barabási-Albert graph.
 Figure 9: Synthetic Cycle and Synthetic BA visualization
Figure 9: Synthetic Cycle and Synthetic BA visualization
In addition, the real-world datasets and meta-learning datasets are also being used in the experiment part. Those are ogbn-arxiv [21], which is a CS citation network. Tissue-PPI [22], which is a protein to protein interaction dataset. Fold-PPI [22], a dataset created by the authors. FirstMM-DB [23], a 3D cloud point dataset. Finally, Tree-of-Life [24], which is another protein-protein interaction dataset.
G-META setups for the different real-world datasets are given below. Following attributes are used for the table comparison:
- Dataset Name(DN)
- G-META task batch size(TBS)
- G-META adapter update learning rate(ALR)
- G-META learner update learning rate(LLR)
- G-META hidden dimensionality size(H)

Table 3: G-META Hyperparameters for different datasets
G-META is compared to different algorithms such as Meta-GNN [25], which applies MAML to Simple Graph Convolution (SGC), ProtoNet [26] which lacks MAML, and MAML which lacks prototypical loss properties of G-META.
The results for these datasets are given below:

Table 4: Graph meta-learning performance on synthetic datasets

Table 5: Graph meta-learning performance on real-world datasets
The results show that for both synthetic and real-world datasets, G-META outperforms all of the other models.
According to these results, using local subgraphs works since Meta-GNN, FS-GIN, and FS-SGC use the entire graph and G-META outperforms them. In addition, G-META outperforms its ablations which are ProtoNet and MAML which lack MAML and Prototypical loss respectively. These results put G-META as a successful graph meta-learning method.
Student's Review
I think the paper is well written. In addition, I think that the visualization is pretty good since the concept is hard to digest. One critic that I can make might be about not including the entire graph in the training as well. Although the local subgraph method works pretty well, indeed works better than methods that use the entire graph; the methods that use the entire graph structure also are successful at some test sets. Thus, I think using both the entire graph structure and local subgraphs would enable G-META to earn higher scores in the test set. However, this will for sure affect the speed of the method; making it a tradeoff between speed and performance.
Another critic that I can make about the paper is about the explanation of the theoretical motivation. Although the concepts such as node influence and graph influence are explained pretty well, their relation to the proofs of the theorems are not explained directly; but rather left as an interpretation of the reader. However, for the reader to understand the relation between these concepts and the theorems; they should skim through the mathematical proof given in the appendix. I think this could be explained a little bit better in the theoretical motivation part.
Finally, I think G-META can be applicable to different medical applications. For example, a lot of data has accumulated from viruses such as coronaviruses and their interaction with different proteins in an animal's or human's body just like Covid-19 and its mutations. If one can use all this data of tasks; one can predict how new mutations of Covid-19 might interact with different proteins in the human body. I think this is a promising research area.
References
[1] Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In KDD, 2018.
[2] Marinka Zitnik, Monica Agrawal, and Jure Leskovec. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics, 34(13):i457–i466, 2018.
[3] Kexin Huang, Cao Xiao, Lucas Glass, Marinka Zitnik, and Jimeng Sun. Skipgnn: Predicting molecular interactions with skip-graph networks. Scientific Reports, 10, 2020.
[4] Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. Heterogeneous graph attention network. In The World Wide Web Conference, pages 2022–2032, 2019.
[5] Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. Heterogeneous graph transformer. In WWW, pages 2704–2710, 2020.
[6] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In ICLR, 2019.
[7] Muhan Zhang and Yixin Chen. Weisfeiler-lehman neural machine for link prediction. In KDD, pages 575–583, 2017.
[8] Thrun S., Pratt L. (eds). Learning to Learn. Springer, Boston, MA. 1998.
[9] Learning. Meta. (n.d.). https://meta-learning.fastforwardlabs.com/.
[10] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In ICML, pages 1126–1135, 2017.
[11] LU LIU, Tianyi Zhou, Guodong Long, Jing Jiang, and Chengqi Zhang. Learning to propagate for graph meta-learning. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alché-Buc, E. Fox, and R. Garnett, editors, NeurIPS, pages 1039–1050, 2019.
[12] Fan Zhou, Chengtai Cao, Goce Trajcevski, Kunpeng Zhang, Ting Zhong, and Ji Geng. Fast network alignment via graph meta-learning. In IEEE INFOCOM 2020-IEEE Conference on Computer Communications, pages 686–695. IEEE, 2020.
[13] Mingyang Chen, Wen Zhang, Wei Zhang, Qiang Chen, and Huajun Chen. Meta relational learning for few-shot link prediction in knowledge graphs. In EMNLP-IJCNLP, Hong Kong, China, November 2019.
[14] Wenhan Xiong, Mo Yu, Shiyu Chang, Xiaoxiao Guo, and William Yang Wang. One-shot relational learning for knowledge graphs. In EMNLP, Brussels, Belgium, 2018.
[15] Mathias Niepert, Mohamed Ahmed, and Konstantin Kutzkov. Learning convolutional neural networks for graphs. In ICML, page 2014–2023, 2016.
[16] Ruo-Chun Tzeng and Shan-Hung Wu. Distributed, egocentric representations of graphs for detecting critical structures. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, ICML, pages 6354–6362, 2019.
[17] Wei-Lin Chiang, Xuanqing Liu, Si Si, Yang Li, Samy Bengio, and Cho-Jui Hsieh. Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks. In KDD, pages 257–266, 2019.
[18] Hanqing Zeng, Hongkuan Zhou, Ajitesh Srivastava, Rajgopal Kannan, and Viktor Prasanna. Graphsaint: Graph sampling based inductive learning method. In ICLR, 2020.
[19] Jie Chen and Yousef Saad. Dense subgraph extraction with application to community detection. IEEE Transactions on knowledge and data engineering, 24(7):1216–1230, 2010.
[20] Karoline Faust, Pierre Dupont, Jérôme Callut, and Jacques Van Helden. Pathway discovery in metabolic networks by subgraph extraction. Bioinformatics, 26(9):1211–1218, 2010.
[21] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. arXiv:2005.00687, 2020.
[22] Marinka Zitnik and Jure Leskovec. Predicting multicellular function through multi-layer tissue networks. Bioinformatics, 33(14):i190–i198, 2017.
[23] Marion Neumann, Plinio Moreno, Laura Antanas, Roman Garnett, and Kristian Kersting. Graph kernels for object category prediction in task-dependent robot grasping. In Online Proceedings of the Eleventh Workshop on Mining and Learning with Graphs, pages 0–6, 2013.
[24] Marinka Zitnik, Marcus W Feldman, Jure Leskovec, et al. Evolution of resilience in protein interactomes across the tree of life. PNAS, 116(10):4426–4433, 2019.
[25] Fan Zhou, Chengtai Cao, Kunpeng Zhang, Goce Trajcevski, Ting Zhong, and Ji Geng. Meta-GNN: On few-shot node classification in graph meta-learning. In CIKM, pages 2357–2360, 2019.
[26] Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. In NeurIPS, pages 4077–4087, 2017.