This blog post is a review of State-Aware Tracker for Real-Time Video Object Segmentation [1] written by Xi Chen, Zuoxin Li, Ye Yuan, Gang Yu, Jianxin Shen, Donglian Qi from the College of Electrical Engineering at Zhejiang University. The research was done at Magvii Inc. and provides a codebase hosted in GitHub for implementation purposes.
Abbreviations
Frames per second (FPS)
Intersection-over-union (IOU)
State-Aware Tracker (SAT)
Stochastic gradient descent (SGD)
Video Object Segmentation (VOS)
Introduction
Segmentation of target objects over video sequences using an initial mask is a basic task for current computer vision algorithms. Semi-Supervised Video Object Segmentation (VOS) uses the initial mask for visual guidance. Since changes to size, orientation, rapid movements and obstructions of the target object and its state often causes deviations from the initial mask in a video, obtaining a robust representation becomes a major challenge for semi-supervised approaches.
VOS uses the additional context information provided in videos. Passing information easily between frames and utilizes previous relations as a hint to improve predictions.
Other methods fall short in combining the speed and accuracy for VOS tasks. They waste the information by ignoring the interframe relations, or computationally inefficient by applying untargeted propagation on the entire image. Furthermore, neglecting possible deviations of the target object leads to instability.
The proposed State-Aware Tracker (SAT) pipeline is designed to obtain a favorable speed-accuracy trade-off in a robust manner. Employing a state estimation-feedback mechanism, see Figure 1, increases stability over time since the model adapts itself for different states depending on the current state. Moreover, tracklets deal with the target object and take advantage of the interframe relations to improve global representation, enhancing the robustness of the visual guidance in a video.
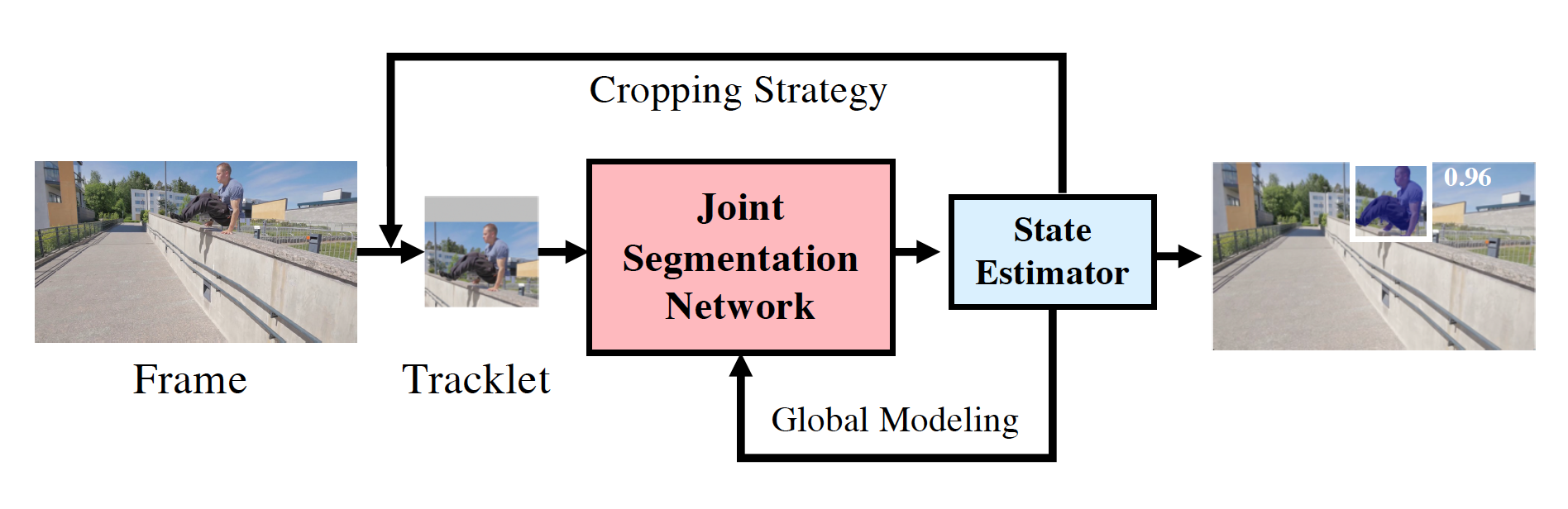
Figure 1. Basic Architecture of SAT
Figure 2 shows a comparison between the novel pipeline and other methods on the DAVIS2017-Val dataset. SAT achieves promising results in terms of a speed-accuracy trade-off. In that benchmarking SAT is the fastest method with a speed of 39 frames per second (FPS), whereas the accuracy for the chosen J&F metric is 72.3%. J measures the region similarity and F the contour accuracy [2].
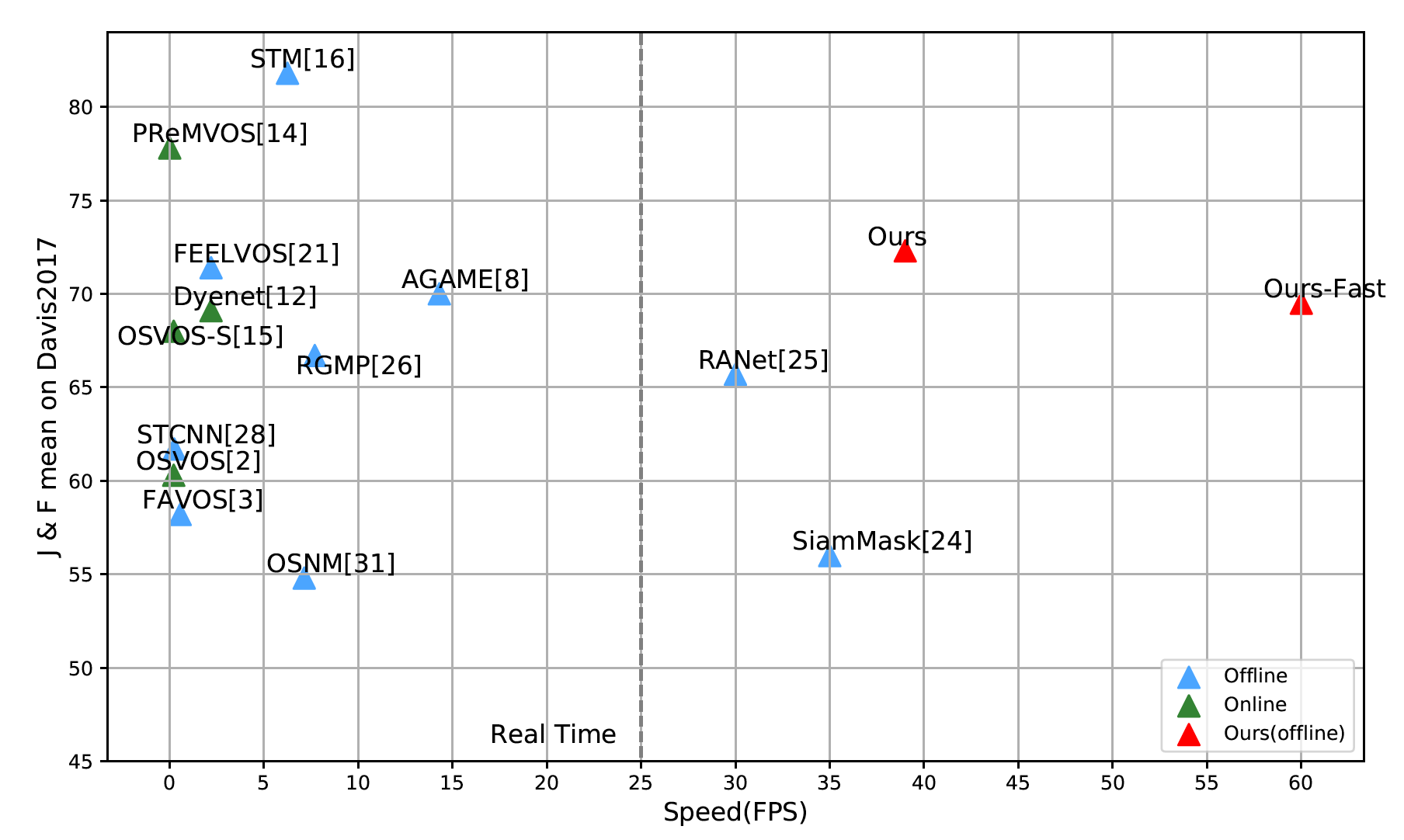
Figure 2. Benchmarking on DAVIS2017-Val dataset.
Related works
Different approaches for segmenting a target object throughout the video sequence using the initial mask are online learning-based, offline learning-based, or tracking-based.
Online learning-based methods employ expensive iterations to fine-tune the network weights using the initial frame, making them computationally inefficient. They do, however, effectively discriminate the target object and make the models more discriminative. OSVOS [3], OnAVOS [4], OSVOS-S [5], and Lucid Tracker [6] are methods in that category.
Offline learning-based methods are suboptimal in terms of information flow, which reduces speed, despite being computationally less expensive compared to online learning-based methods. These methods are inaccurate since the target modeling is not robust. Mask-Track [7], FEELVOS [8], RGMP [9], and AGAME [10] are methods in that category.
Tracking-based methods separate the segmentation outcome from the tracking process, forming an approach similar to post-processing for the tracker. FAVOS [11] and SiamMask [12] are methods in that category.
SAT utilizes the global model via dynamic feature fusion, offline training, tracklets, and uses inter-frame relations, which provides more efficient target modeling, better information flow, and robust guidance. Moreover, tracking and segmentation cooperatively improve each other.
Methodology
Network Overview
Figure 3 shows an overview of the pipeline. The joint segmentation network predicts a mask by decoding the combined features of the similarity encoder, the saliency encoder, and the global feature. The state estimator generates a state score based on the prediction decoded by the network to categorize the state as normal or abnormal. The feedback section contains two loops. The Cropping Strategy Loop stabilizes tracklets by changing the strategy based on the state status. The Global Modeling Loop improves the Joint Segmentation Network via an updated global feature.
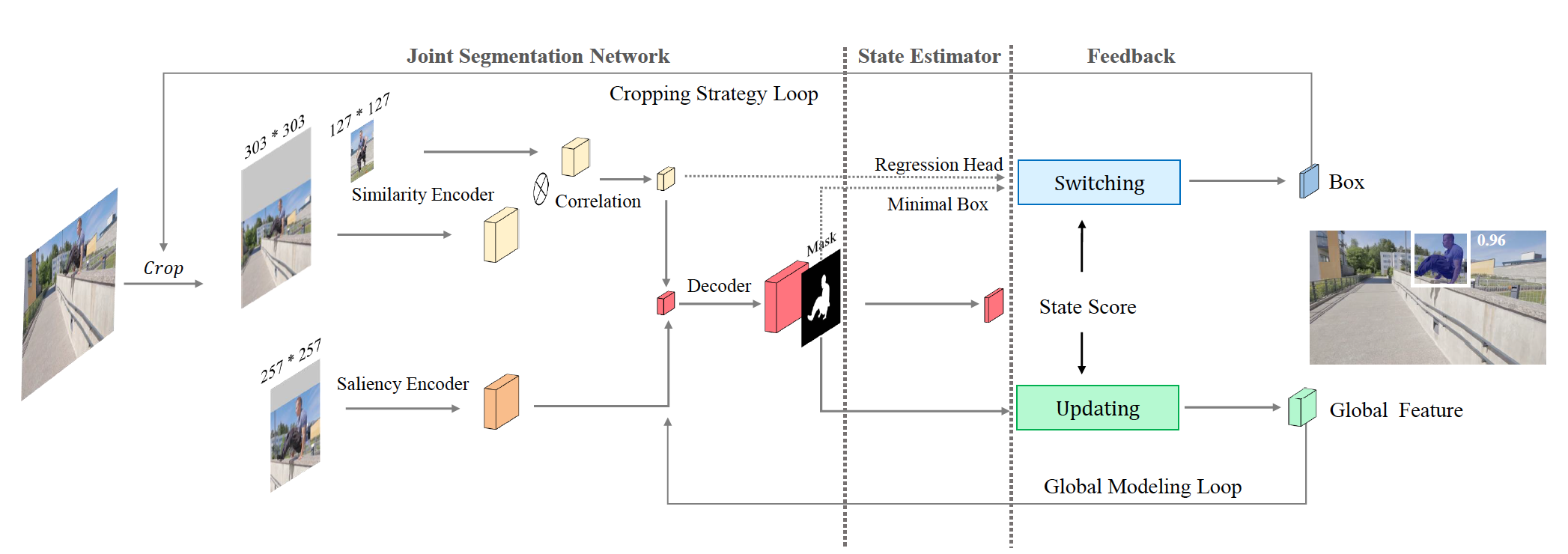
Figure 3. Overview of SAT's main components: The Joint Segmentation Network, State Estimator, and Feedback.
Segmentation
The Saliency Encoder has a shrinked ResNet-50 [13] architecture. The encoder is used to output clean and detailed low-level features of the target object. The input is a cropped and zoomed region around the target. The extracted feature distinguishes fine contours but is not discriminative.
The Similarity Encoder has a SiamFC++ [14] architecture with Alexnet [15] base that encodes the visual correlations between the target object and the current input image. For the target object, the initial frame is used. For the current image, the input is a larger region compared to the saliency encoder. The extracted feature discriminates the target object.
The Joint Segmentation Network fuses the features extracted from the saliency encoder, the similarity encoder, and the global modeling loop. Thus the network decodes a strong high-level feature, which is discriminative and also robust over long periods. Lastly, concatenation of high-level features (obtained by upsampling) and low-level features of the saliency encoder takes place.
Estimation
Throughout a video sequence, the cropped search region needs to be altered at each step. This is tricky because the target object is usually subjected to occlusion and truncation or can even disappear, which makes it difficult to specify a certain cropping strategy. Therefore the pipeline has a state estimator with a state score function to categorize the local states as normal and abnormal. If the target object is well presented the state is normal, whereas occlusion, truncation, and disappearance are abnormal.
The state score (Sstate) is based on the following equations:
| S_{cf} = \frac{\sum_{i,j}^{} P_{i,j} \cdot M_{i,j} }{\sum_{i,j}^{} M_{i,j}} \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, S_{cc} = \frac{ max(\left \{ \left | R_{1}^{c} \right | , \left | R_{2}^{c} , ... , \left | R_{n}^{c} \right | \right | \right \}) }{\sum_{1}^{n} \left | R_{i}^{c} \right |} \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, \, S_{state} = S_{cf} \times S_{cc} |
- Scf : mask prediction confidence
- Scc : geometric concentration for the predicted mask
- Pi,j : mask prediction score at location (i,j)
- Mi,j : predicted binary mask (1 for foreground, 0 otherwise)
- |Ric| : pixel number of the i-th connected region of the predicted mask
If the state score is over some threshold value, in this case 0.85, the state is normal.
Feedback
Cropping Strategy Loop
The main goal of the cropping strategy loop is to improve stability over time depending on the state status.
For normal states in order to show the target position, the smallest bounding box of the largest connected region of the binary mask is calculated. The choice of mask-box for normal states increases the accuracy of the target position.
For abnormal states, on the other hand, in order to obtain a bounding box, a regression head is added to the output of the similarity encoder, followed by temporal smoothness application. The choice of regression box for abnormal states provides more robust predictions.
Global Modeling Loop
This loop improves the high-level representation of the Joint Segmentation Network section by dynamically updating a global feature of the target object. This makes the target representation more general and provides robustness in longer videos.
The global representation G for a given frame T is calculated as follows:
| G_{t} = (1 - S_{state} \cdot \mu ) \cdot G_{t-1} + S_{state} \cdot \mu \cdot F_{t} |
- F : high-level feature of the background filtered image
- \mu : hyperparameter for step length
State score is employed to eliminate the effects of abnormal states while updating the global feature.
Experiments
Network Training
The first training stage employs object tracking datasets and focuses on the similarity encoder and the regression head. In the following step, the weights of the similarity encoder and the regression head stay the same, whereas the complete pipeline is trained using the COCO [16], DAVIS2017 [17], and YouTube-VOS [18] datasets. The employed loss is cross-entropy, the optimizer is stochastic gradient descent (SGD) with momentum and the learning rate is a cosine annealing learning rate except for the first two epochs, in which the learning rate is increasing from 10e-5 to 10e-2.
Ablation Studies
Table 1 shows the results of the ablation study, which validates the importance of each component in the pipeline via a stepwise increase in complexity until the complete SAT architecture is reached.
The baseline used for the study is naive segmentation. This method employs tracklets, combines saliency encoder and decoder, and uses a binary mask to crop a search region. Naive Segmentation performs poorly with a score of 48.1 % and struggles to locate the target object in the case of occlusion, truncation, or disappearance out of the current frame.
The second method is track segmentation. This method utilizes a siamese tracker [19] to localize the target object and combines the tracker with a naive segmentation network to generate a binary mask. This approach improves the performance to 61.6 % but suffers from pose and scale changes.
Correlated feature of the similarity encoder makes the pipeline more discriminative and reaches 63.9 %.
Global Modeling Loop improves the performance of the pipeline to 68.7 %. The middle part of Table 1 breaks down the loop's individual components. The holistic representation improves the pipeline compared by using just the first or first + previous frame. Using the state score contributes to the performance, however, the need for background filtering requires a mask filter.
With the Cropping Strategy Loop, the SAT architecture is completed, and the performance reaches 72.3 %. Changing the box generation method depending on the state not only improves the performance but also reduces the dependency for the tracking and segmentation outputs.
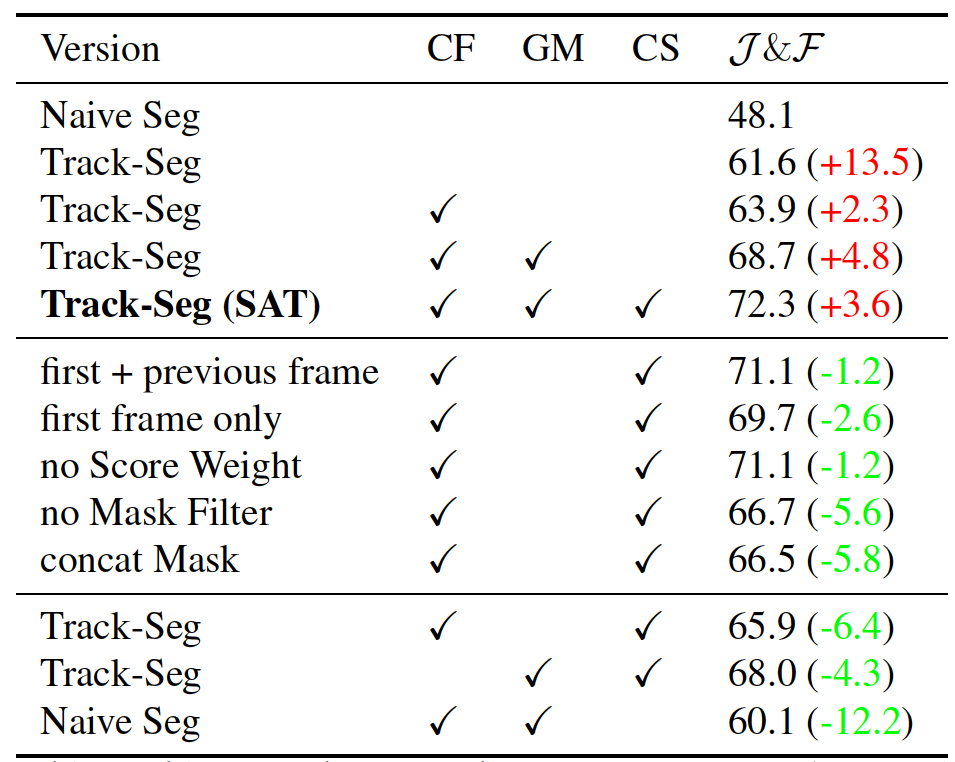
Table 1. Ablation studies on the DAVIS2017-Val dataset. Correlated Feature (CF), Global Modeling Loop (GM), Cropping Strategy Loop (CS), J&F measures accuracy.
Table 2 shows the maximum obtainable performance of SAT. The combination of the mask filter and the bounding box can outperform the individual loops in an ideal condition where the ground truth mask is used.
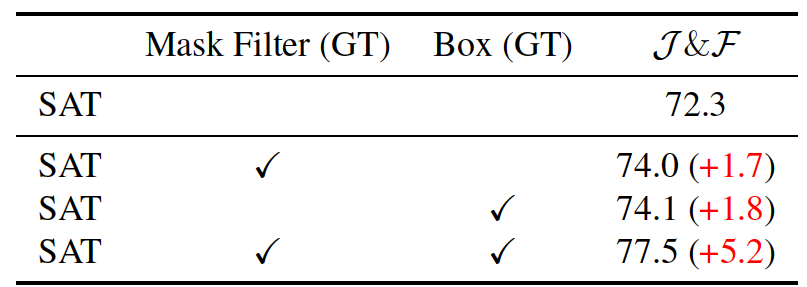
Table 2. Upper-Bound test for SAT.
Comparison to state-of-the-art
SAT performs well on DAVIS2017-Val, DAVIS2016-Val [20], and YouTube-VOS datasets.
On YouTube-VOS SAT performs better than most of the models, except STM [21] that needs relatively more training data and time.
On DAVIS2017 multi-object segmentation task, SAT outperforms most of the models in terms of speed-accuracy trade-off, see Table 3.

Table 3. Results on DAVIS2017. JD denotes performance decay over time. OL stands for online fine-tuning. Ours-Fast denotes SAT with Alexnet backbone
On DAVIS2016 single object segmentation task SAT generates competitive results among offline methods, see Table 4. Online methods are accurate but very inefficient in terms of computation, see FPS column.
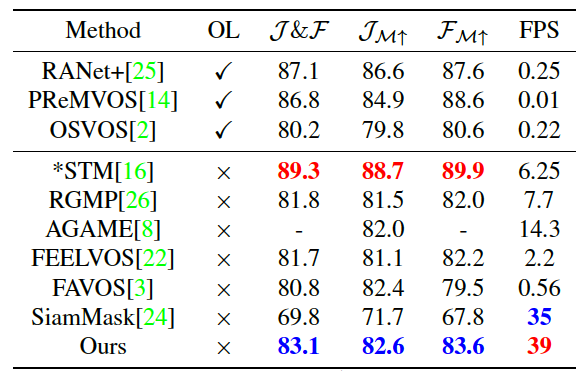
Table 4. Results on DAVIS2016. OL stands for online fine-tuning.
Qualitative result
On the DAVIS benchmarks, even on complicated scenes, SAT can generate robust and accurate results. As mentioned above SAT is designed to be robust and accurate even if the object is subjected to occlusion and truncation thanks to its feedback loops. Figure 4 shows some qualitative results from the benchmark. Even in occluded, complicated, or blurred scenes, SAT delivers robust and accurate results.

Figure 4. SAT on DAVIS Benchmark
Conclusion
The challenge of achieving good results for VOS can be achieved by SAT, which outperforms many other approaches on the speed-accuracy trade-off. Tracklets ensure efficiency, whereas the feedback structure provides stability and robustness.
Student Review
This work shows that a novel approach can significantly improve the results on VOS for speed-accuracy trade-off. SAT is robust in longer video sequences and uses inter-frame relations more efficiently.
The method is well presented, design objectives are well defined and the method is evaluated on different benchmarks. Authors show significant domain knowledge. They present a clear overview of the capabilities of the existing methods and their differences to SAT. They support each new feature and approach with a specific example, which at the same time proves the necessity of the novel approach.
One drawback that can be pointed out is in the comparison of benchmark results. STM method outperforms the SAT on some metrics and the authors argue with the need for larger training data and longer training times. A more in-depth comparison with STM, especially regarding architecture to clarify the significant differences in accuracy and speed would help the readers and also would be a good contribution for future work.
As the authors stated, the fusion of the mask filter and the bounding box can outperform the individual loop. This indicates a very clear and promising direction where future research can be directed and the method can be further improved.
References
- Chen, X., Li, Z., Yuan, Y., Yu, G., Shen, J. and Qi, D., 2020. State-Aware Tracker for Real-Time Video Object Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9384-9393), https://arxiv.org/pdf/2003.00482.pdf
- Perazzi, F., Pont-Tuset, J., McWilliams, B., Van Gool, L., Gross, M. and Sorkine-Hornung, A., 2016. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 724-732)
Sergi Caelles, Kevis-Kokitsi Maninis, Jordi Pont-Tuset, Laura Leal-Taix´e, Daniel Cremers, and Luc Van Gool. Oneshot video object segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 221–230, 2017
Paul Voigtlaender and Bastian Leibe. Online adaptation of convolutional neural networks for the 2017 davis challenge on video object segmentation. In The 2017 DAVIS Challenge on Video Object Segmentation-CVPR Workshops, volume 5, 2017
K-K Maninis, Sergi Caelles, Yuhua Chen, Jordi Pont-Tuset, Laura Leal-Taix´e, Daniel Cremers, and Luc Van Gool. Video object segmentation without temporal information. IEEE transactions on pattern analysis and machine intelligence, 41(6):1515–1530, 2018
Anna Khoreva, Rodrigo Benenson, Eddy Ilg, Thomas Brox, and Bernt Schiele. Lucid data dreaming for object tracking. In The DAVIS Challenge on Video Object Segmentation, 2017
Federico Perazzi, Anna Khoreva, Rodrigo Benenson, Bernt Schiele, and Alexander Sorkine-Hornung. Learning video object segmentation from static images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2663–2672, 2017.
Paul Voigtlaender, Yuning Chai, Florian Schroff, Hartwig Adam, Bastian Leibe, and Liang-Chieh Chen. Feelvos: Fast end-to-end embedding learning for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9481–9490, 2019.
Seoung Wug Oh, Joon-Young Lee, Kalyan Sunkavalli, and Seon Joo Kim. Fast video object segmentation by reference guided mask propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7376–7385, 2018.
Joakim Johnander, Martin Danelljan, Emil Brissman, Fahad Shahbaz Khan, and Michael Felsberg. A generative appearance model for end-to-end video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8953–8962, 2019.
Jingchun Cheng, Yi-Hsuan Tsai, Wei-Chih Hung, Shengjin Wang, and Ming-Hsuan Yang. Fast and accurate online video object segmentation via tracking parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7415–7424, 2018.
Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, and Philip HS Torr. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1328–1338, 2019.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
Yinda Xu, Zeyu Wang, Zuoxin Li, Yuan Ye, and Gang Yu. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. arXiv e-prints, page arXiv:1911.06188, 2019.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675, 2017.
Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, and Thomas Huang. Youtube-vos: Sequence-to-sequence video object segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 585–601, 2018.
Yinda Xu, Zeyu Wang, Zuoxin Li, Yuan Ye, and Gang Yu. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. arXiv e-prints, page arXiv:1911.06188, 2019.
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 724–732, 2016.
Seoung Wug Oh, Joon-Young Lee, Ning Xu, and Seon Joo Kim. Video object segmentation using space-time memory networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 9226–9235, 2019.